
写在前面
正则表达式在处理文本和数据中发挥着不可替代的重要作用,为高级文本模式匹配及搜索-替代等功能提供了基础。在用Sublime博客过程中都会常常用正则表达式来帮助编辑。下面对正则表达式及在Python中的使用做一个简单的总结,帮助自己和看到此文的你来快速写出正确的正则表达式,实现想要实现的功能。
正则表达式
首先介绍正则表达式中特殊符号和字符(统称元字符),正是它们赋予了正则表达式强大的功能和灵活性。
速查手册
最常见的符号和字符、说明及样式样例一览表如下:
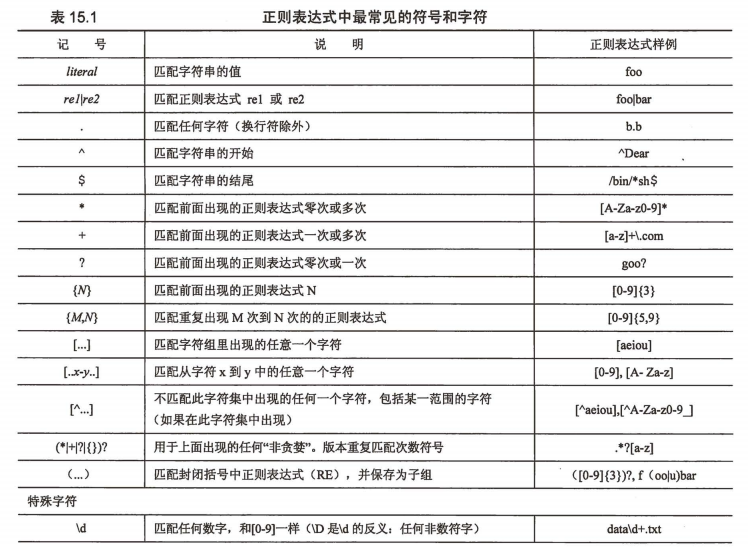

下一部分对表中的内容按功能划分做进一步说明和解释。
对速查手册的进一步解释说明
一、管道符号(|)
管道符号(|)表示的或操作。例:
bat|bet|bit #可以匹配bat或bet或bit多个字符串
二、匹配任意一个单个字符串(.)
句点符号(.)可以匹配除换行符外的任意一个单个字符。例:
f..d #可以匹配在f和d中间的任意两个字符,如food,feed,fabd
三、从字符串开头或结尾或单词边界开始匹配(^, $, \b, \B)
脱字符号(^)指定从字符串开头开始匹配一个模式,美元符号($)则是用来匹配字符串结尾的。例:
^from #匹配任何以from开始的字符串
food$ #匹配任何以food结尾的字符串
\b符号和\B都是用来匹配单词边界的。不同的是,\b匹配的模式是一个单词边界;\B只匹配出现在一个按此终结的模式。例:
\bthe #匹配任何以the开始的字符串
\Bthe #匹配任意包含the但不以the开始的单词
四、创建字符类([])
使用方括号([])的表达式,会匹配方括号内的任何一个字符。例:
b[aeiu]t #可匹配bat, bet, bit, but
五、指定范围(-)和否定(^)
方括号除匹配单个字符外,还可以支持用(-)制定字符范围,如a-z,0-9。如果在左方括号后第一个字符是上箭头符号(^),则表示不匹配指定字符集里的任意字符。例:
z.[r-u] #匹配z符号后面跟任意一个字符,然后再跟一个r, s, t, u中的任意一个字符的字符串
[^aeiou] #匹配一个非元音字符
六、使用闭包操作符(*, +, ?, {})实现多次出现/重复匹配
星号(*)表示匹配它左边的正则表达模式零次或以上
加号(+)表示匹配它左边的正则表达模式一次或以上
问号(?)表示匹配他左边的正则表达模式零次或一次
花边符号({}),里面可以是单个数,也可以是一对值,如{N}表示匹配N次,{M,N}表示匹配M次到N次。
a*b+c?[0-9]{11,15} #匹配开始为零个或以上,后面跟一个以上的b和最多一个c和11到15个数字的字符串
七、特殊字符表示、字符集
符号\d可以表示0-9这个范围内的十进制数字。
符号\w可以表示整个字符数字的字符集,相当于A-Za-z0-9。
符号\s表示空白字符。
这些字符的大写形式表示相反的含义,即不匹配。
八、用圆括号(())组建组
圆括号(())和正则表达式一起使用时可以实现以下任意一个(或两个)功能:
(1)对正则表达式进行分组,例如用两个不同的正则表达式去比较一个字符串或为整个表达式添加重复操作符;
(2)匹配子组,将匹配到的子串保存到一个子组,便于以后使用。
\d+(\.\d*)? #匹配简单浮点数,同时,如果有小数点后,会将其存入子组。
正则表达式的Python实践
掌握正则表达式的基础知识后,下面介绍下Python默认的正则表达式模块re模块,用其进行文本和数据的处理。
速查手册
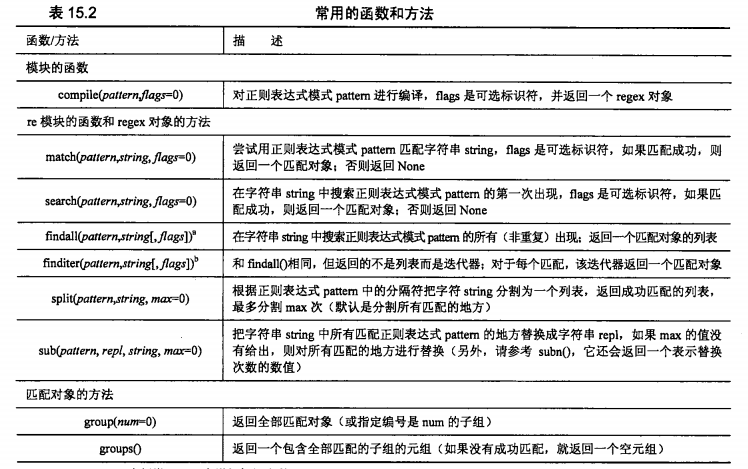
对速查手册的进一步解释说明
一、compile()函数
compile()可根据一个模式字符串和可选的标志参数生成一个正则表达式对象,该对象拥有一系列方法用于正则表达式的匹配和替换(re模块提供了与这些方法功能完全一致的函数,这些函数使用模式字符串直接作为它们的第一个参数)。
对于程序频繁使用的表达式,编译(使用compile)这些表达式会更为高效。
二、用matchd()匹配字符串
match()函数会尝试从字符串的开头开始对模式进行匹配,如果匹配成功,就返回一个匹配对象,如果匹配失败,返回None。
三、用search()在一个字符串中查找一个模式
match()只会尝试从字符串起始处进行匹配模式(即从字符串的开头进行匹配),如果你要搜索的模式出现在字符串中间的概率比出现在开头的更大,则需要使用search()。search会检查参数字符串任意位置的地方给定正则表达式模式的匹配情况(即从字符串的任意位置开始匹配)。这也是匹配和搜索的区别。
四、用group()、groups()返回匹配对象
group()方法或者返回所有匹配对象或是指定的子组;groups()返回一个包含唯一或所有子组的元祖。例:
>>> m=re.match('(\w\w\w)-(\d\d\d)','abc-123')
>>> m.group()
'abc-123'
>>> m.group(1)
'abc'
>>> m.groups()
('abc','123')
五、用findall()找到每个出现的匹配部分
findall用于非重叠的搜索某字符串中一个正则表达式模式出现的情况,返回列表。例:
>>> re.findall('car','carry the barcardi to the car')
['car','car','car']
六、用sub()(和subn())进行搜索和替换
subn和sub几乎一样,不同之处是subn返回替换次数的数字。例:
>>> re.sub('[ae]','X','abcdef')
'XbcdXf'
七、用split()进行分割
正则表达式的split()与字符串的split()相似,前后根据增则表达式模式分割字符串,显著提升了字符分割的能力。例:
对于登陆系统的用户的信息:
'wesc pts/9 Jun 20 20:33 (192.168.0.6)'
可以用下面的正则分割
>>>re.split('\s\s+|\t',str) #str为上述字符串,匹配模式的含义是至少两个空白字符或者单个TAB符号
['wesc','pts/9','Jun 20 20:33','(192.168.0.6)']
八、用(?)实现非贪婪匹配
对于字符串:
'Thu Feb 15 uzifzf@dpyivihw.gov::1171590364-6-8'
如果我们想截获末尾数字的字段
>>> patt = '.+(\d+-\d+-\d+)'
>>> re.match(patt,str).group(1) #str是上述字符串
'4-6-8'
我们发现并不是想象的这样,因为正则表达式本事模式的是贪心匹配,也就是从左到右尽量抓取最长的字符串。
我们可以使用“非贪婪”操作符“?”来解决问题。
>>> patt='.+?(\d+-\d+-\d+)'
>>> re.match(patt,str).group(1)
1171590364-6-8
小结
上述部分是对《Python核心编程》一书中正则表达式一章的读书简记,供快速参考查询。想要对正则表达式做深入理解的,可以去看资料[2]。
参考文献
[1] Python核心编程 第二版. Wesley J.Chun。
[2] 精通正则表达式 第三版. Jeffrey E.F.Friedl



