
写在前面
上一篇文章介绍了如何使用Keras实现VGGNet(14年的ImageNet亚军),本篇介绍14年ImageNet的冠军Inception V1,它最大的特点是控制了计算量和参数量的同时,获得了非常好的分类性能——top-5错误率6.67%,只有AlexNet的一半不到。Inception 1属于GoogLeNet网络系列的一个V1版本,后续出现了V2,V3,V4升级版本。本篇首先详细介绍最经典的Inception V1网络的技术要点、网络结构和代码实现,最后对V2,V3,V4升级版本做延伸介绍。
技术要点
一、打破了常规的卷积层串联的模式,提出了将1x1,3x3,5x5的卷积层和3x3的pooling池化层并联组合后concatenate组装在一起的设计思路。
二、Inception V1降低了参数量,目的有两个:1 参数越多模型越大,需要提供模型学习的数据量就越大,数据量不大的情况下容易过拟合;2 参数越多,耗费的计算资源也会更大。
三、去除了最后的全连接层,用全局平均池化层来取代它。全连接层几乎占据了AlexNet或VGGNet中90%的参数量,而且会引起过拟合,去除全连接层后模型训练更快并且减轻了过拟合。用全局平均池化层取代全连接层的做法借鉴了Network In Network(以下简称NIN)论文。
四、Inception V1中精心设计的InceptionModule提高了参数的利用效率。这一部分也借鉴了NIN的思想,形象的解释就是Inception Module本身如同大网络中的一个小网络,其结构可以反复堆叠在一起形成大网络。Inception V1比NIN更进一步的是增加了分支网络,NIN则主要是级联的卷积层和MLPConv层。一般来说卷积层要提升表达能力,主要依靠增加输出通道数,但副作用是计算量增大和过拟合。每一个输出通道对应一个滤波器,同一个滤波器共享参数,只能提取一类特征,因此一个输出通道只能做一种特征处理。而NIN中的MLPConv则拥有更强大的能力,允许在输出通道之间组合信息,因此效果明显。可以说,MLPConv基本等效于普通卷积层后再连接1*1的卷积和ReLU激活函数。
网络结构
一、InceptionModule
InceptionModule结构图如下。其由四个分支构成:第一个分支直接对输入进行1*1的卷积;第二个分支线进行1*1的卷积,然后连接3*3卷积,相当于两次特征变换;第三个分支先是1*1卷积,然后连接5*5卷积;最后一个分支线进行3*3最大池化,然后1*1卷积。所有的分支都是用1*1,一个原因是因为1*1卷积的性价比很高,用很小的计算量就能增加一层特征变换和非线性化。Inception Module中包含了3种不同尺寸的卷积和1个最大池化,增加了网络对不同尺度的适应性,这一部分和Multi-Scale的思想类似。InceptionModule可以让网络的深度和宽度高效率地扩充,提升准确率且不致于过拟合。
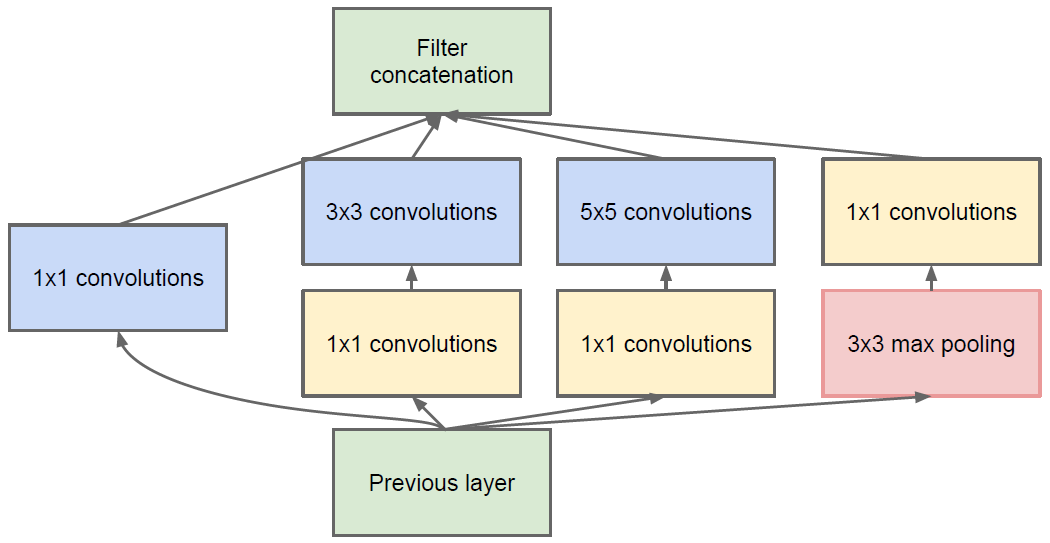
稀疏结构是非常适合神经网络的一种结构,尤其是对非常大型、非常深的神经网络,可以减轻过拟合并降低计算量,例如卷积神经网络就是稀疏的连接。Inception Net的主要目标就是找到最优的稀疏结构单元Inception Module,论文中提到其稀疏结构基于Hebbian原理,这里简单解释一下Hebbian原理:神经反射活动的持续与重复会导致神经元连接稳定性的持久提升,当两个神经元细胞A和B距离很近,并且A参与了对B重复、持续的兴奋,那么某些代谢变化会导致A将作为能使B兴奋的细胞。总结一下即“一起发射的神经元会连在一起”(Cells that fire together, wire together),学习过程中的刺激会使神经元间的突触强度增加。受Hebbian原理启发,另一篇文章Provable Bounds for Learning Some Deep Representations提出,如果数据集的概率分布可以被一个很大很稀疏的神经网络所表达,那么构筑这个网络的最佳方法是逐层构筑网络:将上一层高度相关的节点聚类,并将聚类出来的每一个小簇(cluster)连接到一起。
因此一个“好”的稀疏结构,应该是符合Hebbian原理的,我们应该把相关性高的一簇神经元节点连接在一起。在图片数据中,天然的就是临近区域的数据相关性高,因此相邻的像素点被卷积操作连接在一起。而我们可能有多个卷积核,在同一空间位置但在不同通道的卷积核的输出结果相关性极高。因此,一个1*1的卷积就可以很自然地把这些相关性很高的、在同一个空间位置但是不同通道的特征连接在一起,这就是为什么1*1卷积这么频繁地被应用到Inception Net中的另一个原因。1*1卷积所连接的节点的相关性是最高的,而稍微大一点尺寸的卷积,比如3*3、5*5的卷积所连接的节点相关性也很高,因此也可以适当地使用一些大尺寸的卷积,增加多样性(diversity)。Inception Module通过4个分支中不同尺寸的1*1、3*3、5*5等小型卷积将相关性很高的节点连接在一起,就完成了其设计初衷,构建出了很高效的符合Hebbian原理的稀疏结构。
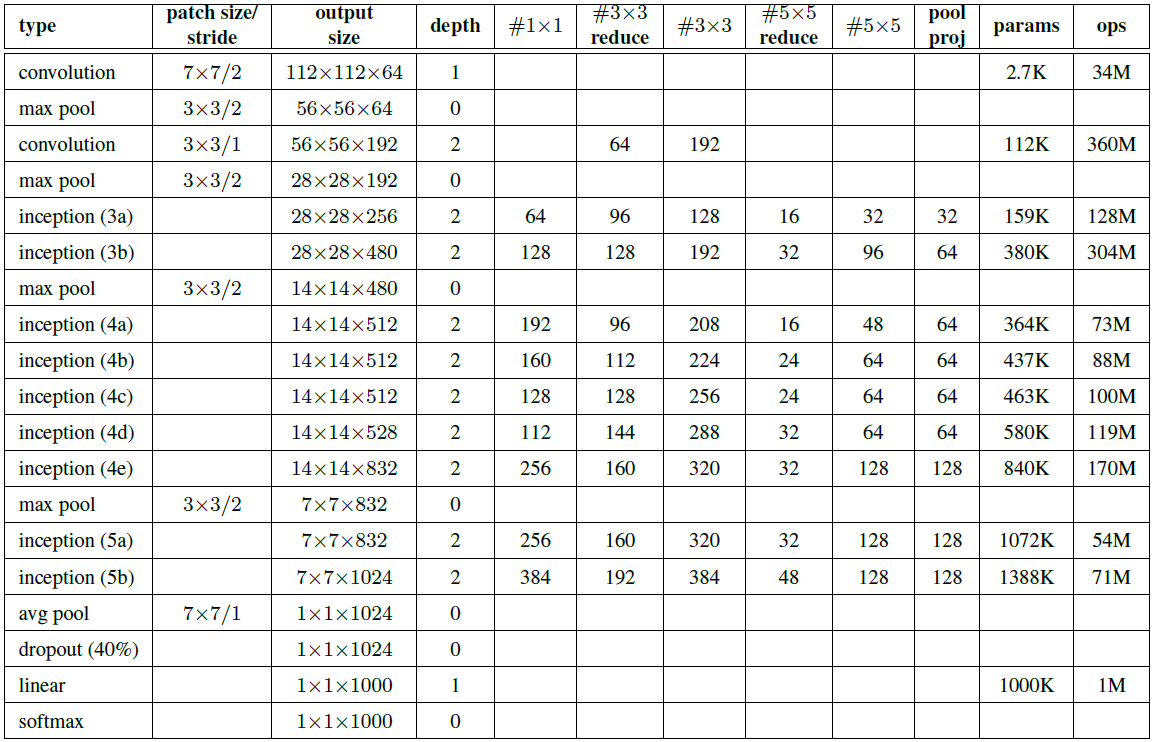
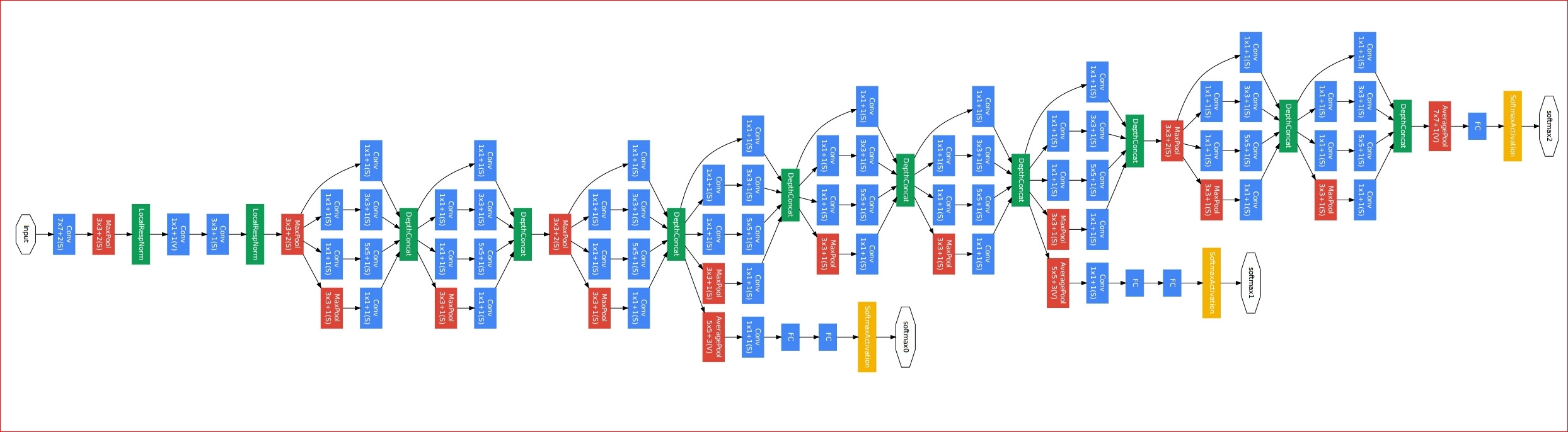
二、网络整体结构
网络整体结构构见下面两幅图。需要注意,为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度。
代码
#-*- coding: UTF-8 -*-
"""
Author: lanbing510
Environment: Keras2.0.5,Python2.7
Model: GoogLeNet Inception V1
"""
from keras.layers import Conv2D, MaxPooling2D, AveragePooling2D, ZeroPadding2D
from keras.layers import Flatten, Dense, Dropout
from keras.layers import Input, concatenate
from keras.models import Model
from keras import regularizers
from keras.utils import plot_model
from KerasLayers.Custom_layers import LRN2D
# Global Constants
NB_CLASS=1000
LEARNING_RATE=0.01
MOMENTUM=0.9
ALPHA=0.0001
BETA=0.75
GAMMA=0.1
DROPOUT=0.4
WEIGHT_DECAY=0.0005
LRN2D_NORM=True
DATA_FORMAT='channels_last' # Theano:'channels_first' Tensorflow:'channels_last'
USE_BN=True
def conv2D_lrn2d(x,filters,kernel_size,strides=(1,1),padding='same',data_format=DATA_FORMAT,dilation_rate=(1,1),activation='relu',use_bias=True,kernel_initializer='glorot_uniform',bias_initializer='zeros',kernel_regularizer=None,bias_regularizer=None,activity_regularizer=None,kernel_constraint=None,bias_constraint=None,lrn2d_norm=LRN2D_NORM,weight_decay=WEIGHT_DECAY):
if weight_decay:
kernel_regularizer=regularizers.l2(weight_decay)
bias_regularizer=regularizers.l2(weight_decay)
else:
kernel_regularizer=None
bias_regularizer=None
x=Conv2D(filters=filters,kernel_size=kernel_size,strides=strides,padding=padding,data_format=data_format,dilation_rate=dilation_rate,activation=activation,use_bias=use_bias,kernel_initializer=kernel_initializer,bias_initializer=bias_initializer,kernel_regularizer=kernel_regularizer,bias_regularizer=bias_regularizer,activity_regularizer=activity_regularizer,kernel_constraint=kernel_constraint,bias_constraint=bias_constraint)(x)
if lrn2d_norm:
x=LRN2D(alpha=ALPHA,beta=BETA)(x)
return x
def inception_module(x,params,concat_axis,padding='same',data_format=DATA_FORMAT,dilation_rate=(1,1),activation='relu',use_bias=True,kernel_initializer='glorot_uniform',bias_initializer='zeros',kernel_regularizer=None,bias_regularizer=None,activity_regularizer=None,kernel_constraint=None,bias_constraint=None,lrn2d_norm=LRN2D_NORM,weight_decay=None):
(branch1,branch2,branch3,branch4)=params
if weight_decay:
kernel_regularizer=regularizers.l2(weight_decay)
bias_regularizer=regularizers.l2(weight_decay)
else:
kernel_regularizer=None
bias_regularizer=None
pathway1=Conv2D(filters=branch1[0],kernel_size=(1,1),strides=1,padding=padding,data_format=data_format,dilation_rate=dilation_rate,activation=activation,use_bias=use_bias,kernel_initializer=kernel_initializer,bias_initializer=bias_initializer,kernel_regularizer=kernel_regularizer,bias_regularizer=bias_regularizer,activity_regularizer=activity_regularizer,kernel_constraint=kernel_constraint,bias_constraint=bias_constraint)(x)
pathway2=Conv2D(filters=branch2[0],kernel_size=(1,1),strides=1,padding=padding,data_format=data_format,dilation_rate=dilation_rate,activation=activation,use_bias=use_bias,kernel_initializer=kernel_initializer,bias_initializer=bias_initializer,kernel_regularizer=kernel_regularizer,bias_regularizer=bias_regularizer,activity_regularizer=activity_regularizer,kernel_constraint=kernel_constraint,bias_constraint=bias_constraint)(x)
pathway2=Conv2D(filters=branch2[1],kernel_size=(3,3),strides=1,padding=padding,data_format=data_format,dilation_rate=dilation_rate,activation=activation,use_bias=use_bias,kernel_initializer=kernel_initializer,bias_initializer=bias_initializer,kernel_regularizer=kernel_regularizer,bias_regularizer=bias_regularizer,activity_regularizer=activity_regularizer,kernel_constraint=kernel_constraint,bias_constraint=bias_constraint)(pathway2)
pathway3=Conv2D(filters=branch3[0],kernel_size=(1,1),strides=1,padding=padding,data_format=data_format,dilation_rate=dilation_rate,activation=activation,use_bias=use_bias,kernel_initializer=kernel_initializer,bias_initializer=bias_initializer,kernel_regularizer=kernel_regularizer,bias_regularizer=bias_regularizer,activity_regularizer=activity_regularizer,kernel_constraint=kernel_constraint,bias_constraint=bias_constraint)(x)
pathway3=Conv2D(filters=branch3[1],kernel_size=(5,5),strides=1,padding=padding,data_format=data_format,dilation_rate=dilation_rate,activation=activation,use_bias=use_bias,kernel_initializer=kernel_initializer,bias_initializer=bias_initializer,kernel_regularizer=kernel_regularizer,bias_regularizer=bias_regularizer,activity_regularizer=activity_regularizer,kernel_constraint=kernel_constraint,bias_constraint=bias_constraint)(pathway3)
pathway4=MaxPooling2D(pool_size=(3,3),strides=1,padding=padding,data_format=DATA_FORMAT)(x)
pathway4=Conv2D(filters=branch4[0],kernel_size=(1,1),strides=1,padding=padding,data_format=data_format,dilation_rate=dilation_rate,activation=activation,use_bias=use_bias,kernel_initializer=kernel_initializer,bias_initializer=bias_initializer,kernel_regularizer=kernel_regularizer,bias_regularizer=bias_regularizer,activity_regularizer=activity_regularizer,kernel_constraint=kernel_constraint,bias_constraint=bias_constraint)(pathway4)
return concatenate([pathway1,pathway2,pathway3,pathway4],axis=concat_axis)
def create_model():
if DATA_FORMAT=='channels_first':
INP_SHAPE=(3,224,224)
img_input=Input(shape=INP_SHAPE)
CONCAT_AXIS=1
elif DATA_FORMAT=='channels_last':
INP_SHAPE=(224,224,3)
img_input=Input(shape=INP_SHAPE)
CONCAT_AXIS=3
else:
raise Exception('Invalid Dim Ordering: '+str(DIM_ORDERING))
x=conv2D_lrn2d(img_input,64,(7,7),2,padding='same',lrn2d_norm=False)
x=MaxPooling2D(pool_size=(3,3),strides=2,padding='same',data_format=DATA_FORMAT)(x)
x=LRN2D(alpha=ALPHA,beta=BETA)(x)
x=conv2D_lrn2d(x,64,(1,1),1,padding='same',lrn2d_norm=False)
x=conv2D_lrn2d(x,192,(3,3),1,padding='same',lrn2d_norm=True)
x=MaxPooling2D(pool_size=(3,3),strides=2,padding='same',data_format=DATA_FORMAT)(x)
x=inception_module(x,params=[(64,),(96,128),(16,32),(32,)],concat_axis=CONCAT_AXIS) #3a
x=inception_module(x,params=[(128,),(128,192),(32,96),(64,)],concat_axis=CONCAT_AXIS) #3b
x=MaxPooling2D(pool_size=(3,3),strides=2,padding='same',data_format=DATA_FORMAT)(x)
x=inception_module(x,params=[(192,),(96,208),(16,48),(64,)],concat_axis=CONCAT_AXIS) #4a
x=inception_module(x,params=[(160,),(112,224),(24,64),(64,)],concat_axis=CONCAT_AXIS) #4b
x=inception_module(x,params=[(128,),(128,256),(24,64),(64,)],concat_axis=CONCAT_AXIS) #4c
x=inception_module(x,params=[(112,),(144,288),(32,64),(64,)],concat_axis=CONCAT_AXIS) #4d
x=inception_module(x,params=[(256,),(160,320),(32,128),(128,)],concat_axis=CONCAT_AXIS) #4e
x=MaxPooling2D(pool_size=(3,3),strides=2,padding='same',data_format=DATA_FORMAT)(x)
x=inception_module(x,params=[(256,),(160,320),(32,128),(128,)],concat_axis=CONCAT_AXIS) #5a
x=inception_module(x,params=[(384,),(192,384),(48,128),(128,)],concat_axis=CONCAT_AXIS) #5b
x=AveragePooling2D(pool_size=(7,7),strides=1,padding='valid',data_format=DATA_FORMAT)(x)
x=Flatten()(x)
x=Dropout(DROPOUT)(x)
x=Dense(output_dim=NB_CLASS,activation='linear')(x)
x=Dense(output_dim=NB_CLASS,activation='softmax')(x)
return x,img_input,CONCAT_AXIS,INP_SHAPE,DATA_FORMAT
def check_print():
# Create the Model
x,img_input,CONCAT_AXIS,INP_SHAPE,DATA_FORMAT=create_model()
# Create a Keras Model
model=Model(input=img_input,output=[x])
model.summary()
# Save a PNG of the Model Build
plot_model(model,to_file='GoogLeNet.png')
model.compile(optimizer='rmsprop',loss='categorical_crossentropy')
print 'Model Compiled'
if __name__=='__main__':
check_print()
Inception V1网络的其他升级版本(V2,V3,V4)
一、 Inception V2的网络在Inception v1的基础上,进行了改进,一方面了加入了BN层,减少了Internal Covariate Shift(内部神经元分布的改变),使每一层的输出都规范化到一个N(0, 1)的高斯,还去除了Dropout、LRN等结构;另外一方面学习VGG用2个3x3的卷积替代inception模块中的5x5卷积,既降低了参数数量,又加速计算。
二、Inception V3一个最重要的改进是分解(Factorization),将7x7分解成两个一维的卷积(1x7,7x1),3x3也是一样(1x3,3x1)。这样的好处,既可以加速计算(多余的计算能力可以用来加深网络),又可以将1个conv拆成2个conv,使得网络深度进一步增加,增加了网络的非线性,可以处理更多更丰富的空间特征,增加特征多样性。还有值得注意的地方是网络输入从224x224变为了299x299,更加精细设计了35x35/17x17/8x8的模块。
三、Inception V4结合了微软的ResNet,发现ResNet的结构可以极大地加速训练,同时性能也有提升,得到一个Inception-ResNet V2网络,同时还设计了一个更深更优化的Inception V4模型,能达到与Inception-ResNet V2相媲美的性能。
参考文献
[1] Inception V1, Going Deeper withConvolutions.
[2] Inception V2, Batch Normalization:Accelerating Deep Network Training by Reducing Internal Covariate Shift.
[3] Inception V3,Rethinking theInception Architecture for Computer Vision.
[4] Inception V4, Inception-v4,Inception-ResNet and the Impact of Residual Connections on Learning.



