
写在前面
Python核心编程来来回回读过两三遍,很棒的书,尤其作为速查手册使用时。最近计划对其每一部分进行整理,一方面加深对Python的理解,另一方面方便以后在手头没有核心编程时能进行快速查询。本篇主要整理关于Python序列(字符串、列表、元祖)的部分,第一部分是对序列的整理,后面部分分别对字符串,列表,元祖进行展开。
序列
下面分别介绍适用于所有序列类型的标准操作符,序列类型操作符及内建函数。
标准类型操作符
标准类型操作符一般都能适用于所有的序列类型(除作复合类型对象的比较外)。下面是标准类型操作符一览表:
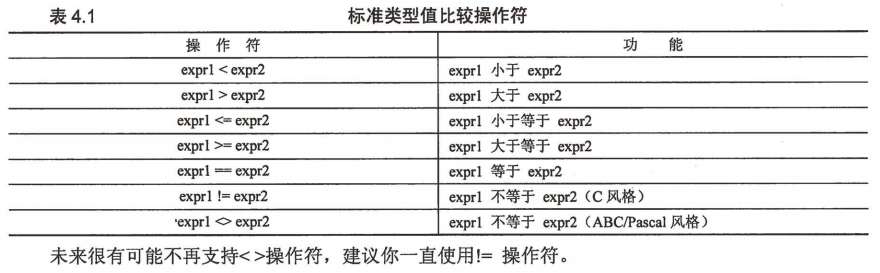
序列类型操作符
一、速查手册
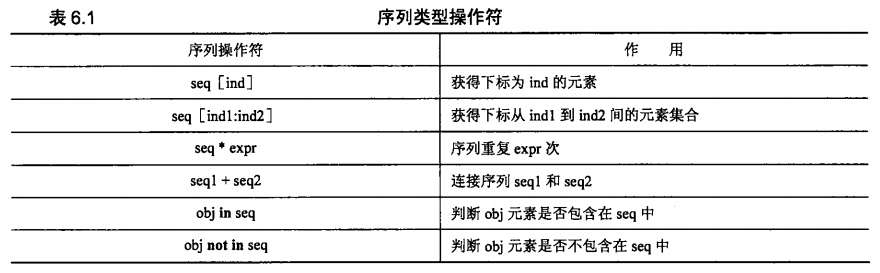
二、对速查手册的一些补充说明
切片操作符的一些说明:
>>> s='abcdefgh'
>>> s[0:3] #[1,3)不包括3
'abc'
>>> s[::2] #用步长索引进行扩展的切片操作
'aceg'
>>> s='abcde'
>>> for i in [None]+range(-1,-len(s),-1): #使用None作为索引值来实现s[:-1]打印出abcde
... print s[:i]
...
abcde
abcd
abc
ab
a
内建函数(BIF)
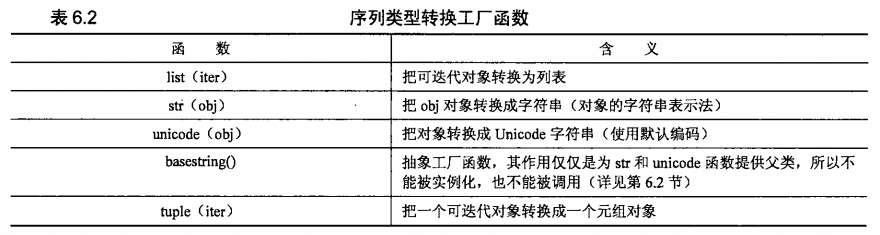
一、序列类型转换工厂函数
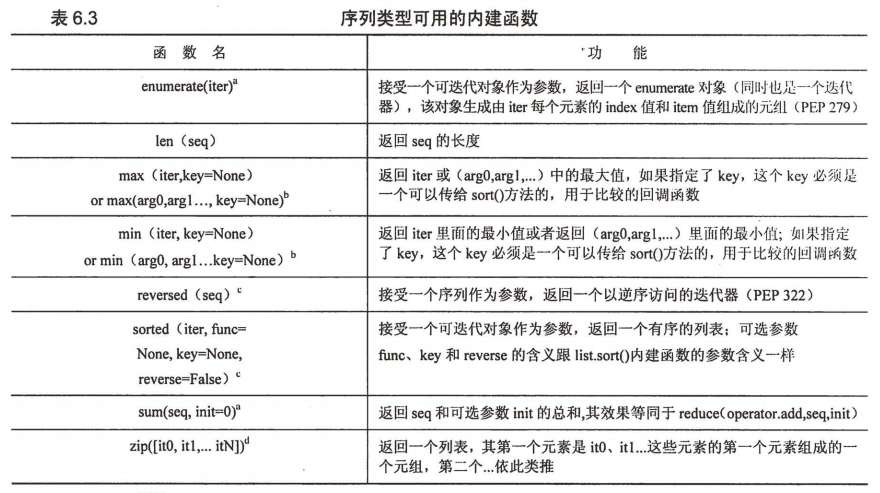
二、序列类型可用的内建函数
字符串
字符串是Python里最常见的类型,可以简单的通过引号包含或者str()创建通常的字符串,或是unicode()、u+引号包含创建Unicode字符串,他们都是抽象类basestring的子类。
一、字符串特有的操作符
字符串除了可以使用上述序列操作符外,还有一些其特有的操作符
1 编译时字符串连接。
>>> foo="Hello" "World"
>>> foo
'HelloWorld'
通过这种方法可以把字符串分几部分来写,而不用加反斜杠,这样的好处是你可以把注释加进来,如:
>>> f=urllib.urlopen('http://' #protocol
... 'localhost' #hostname
... ':8000') #port
2 普通字符转换为Unicode字符串
如果把一个普通字符串和一个Unicode字符串做连接处理,Python会自动将普通字符串转换为Unicode字符串。
>>> 'Hello'+u' '+'World'
u'Hello World'
3 原始字符串操作符(r/R)
>>> path=r'C:\windows\temp'
>>> path
'C:\\windows\\temp'
4 三引号
三引号可以保持其包含的字符的格式,让程序员从引号和特殊符号的泥潭里解脱出来。
二、格式化操作符
字符串格式化符号一览表:
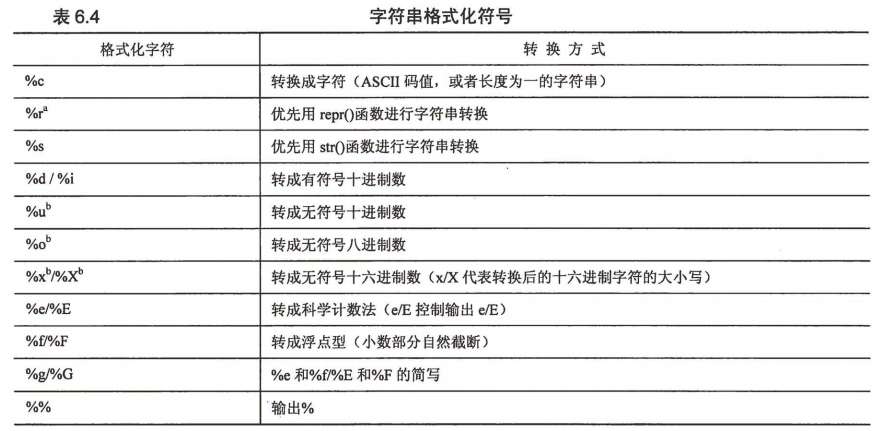
格式化操作符辅助指令一览表:
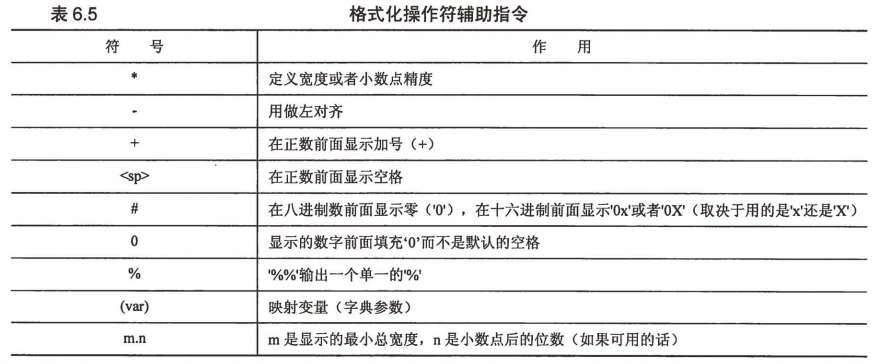
一些例子:
>>> 'Host: %s\tPort: %d %0.2f %#x' % ('mars',80,1234.56,108)
'Host: mars\tPort: 80 1234.56 0x6c'
三、字符串模板
字符串格式化操作符很酷易用上手快,但它的一个缺点是不是那么直观。字符串模板则克服了这个缺点,类似于shell风格的$。
>>> from string import Template
>>> s=Template('There are ${howmany} ${lang} Quotation Symbols')
>>>
>>> print s.substitute(lang='Python', howmany=3)
There are 3 Python Quotation Symbols
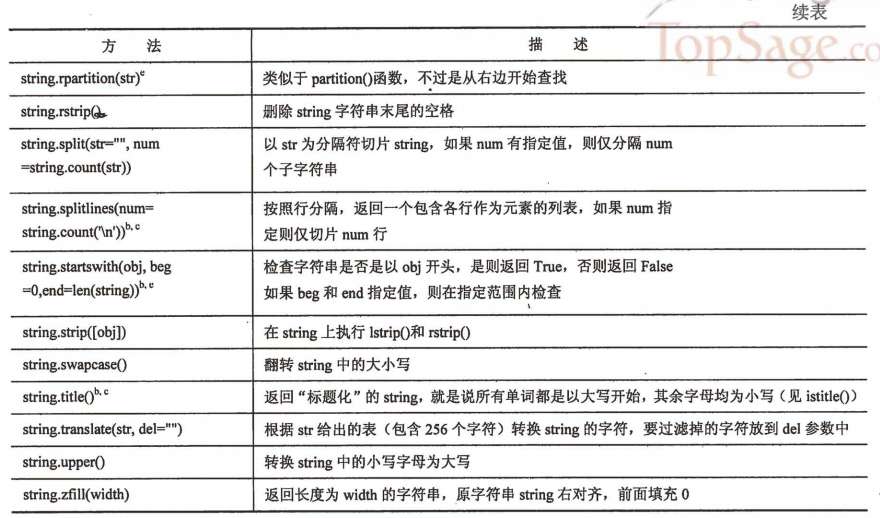
四、字符串内建函数
字符串内建方法一览表:
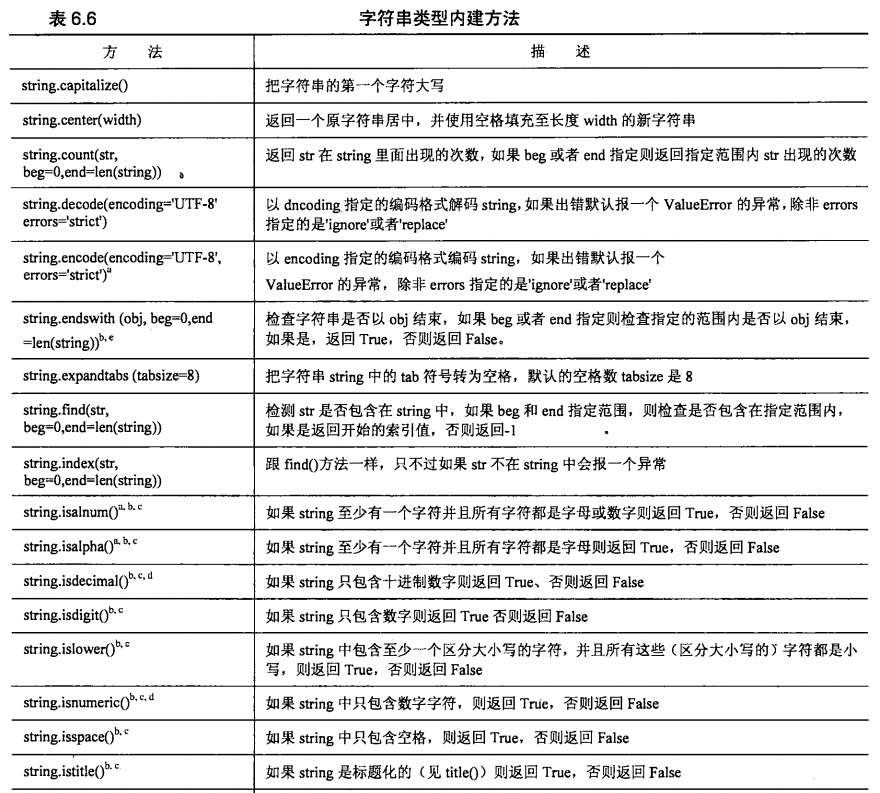
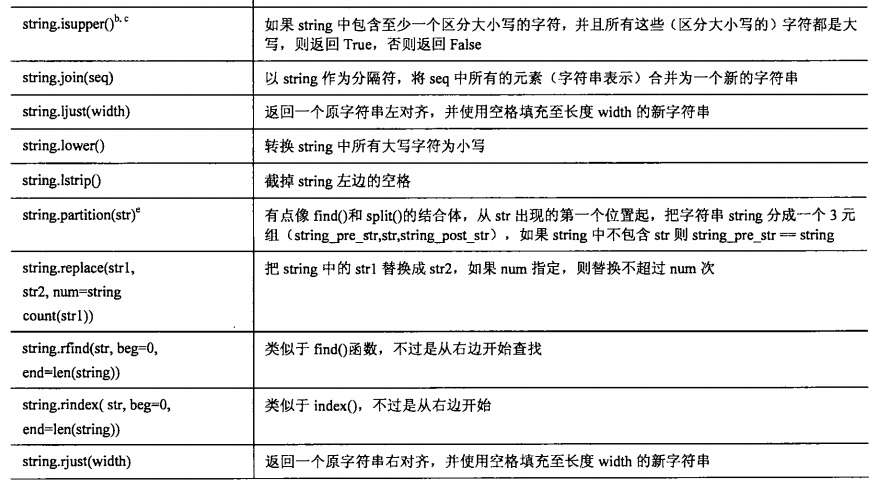
五、Unicode
字符编码是让程序员很头疼的一件事情,不留神就会碰到编解码错误。搞清Unicode,ASCII,GBK,GBK2312,UTF-8,UTF-16,UTF-32等等之间的关系很有必要。
首先Unicode,ASCII,GBK,GBK2312属于编码字符集,即每个字符都有唯一的整数编号,每个字符都有自己特有的编号,同一个字符在不同编码字符集中编号也会不同,很多编码字符集都是ASCII的超集,比如英文字母“A”,在ASCII及Unicode及GB2312中,均是第0x41个字符。
UTF-8,UTF-16,UTF-32是对Unicode编码字符集的不同编码方式。但你可能就问了,常常听人说使用ASCII,GBK2312为什么经常和UTF-8这些并列,他们前者不是编码字符集,后者是编码方式吗?前者是编码字符集没有错,但是对于ASCII或者GB2312都只有唯一一种编码,那么我称呼它们为ASCII编码或者GB2312编码也没有问题。
那为什么不像ASCII一样直接用Unicode编码方式,还要有UTF-8等编码?因为Unicode字符集太大,都用很多字节表示的话会占很多空间,使用UTF-8等编码方案会节约存储空间。比如对于UTF-8编码方案,255以下的Unicode字符编号不做变换,以后的做编码,所以对于UTF-8,字符数字占一个字节,汉子占三个字节,不用都分配好几个字节了。感兴趣的可以通过参考[3]进行深入研究。
弄清这些概念后下面列举一些Python下Unicode的使用及注意事项,可以避免90%由Unocode字符串引起的bug。
1 不要使用str()函数,用unicode()代替。unicode(),unichar()可以看成Unicode版本的str(),char(),后者默认只能处理常规的ASCII编码。
2 程序中出现字符串,一定要加个前缀u。
3 不要使用过时的string模块。
4 不到必须时不要在程序里编解码Unicode字符。只在你要写入文件或数据库或者网络时才调用encode()函数;相应的只在你需要把数据读回来的时候才调用decode()函数。
5 Python标准库绝大部分模块都是兼容Unicode的,除了pickle模块,使用此模块时一定要先转换为ASCII字符串。
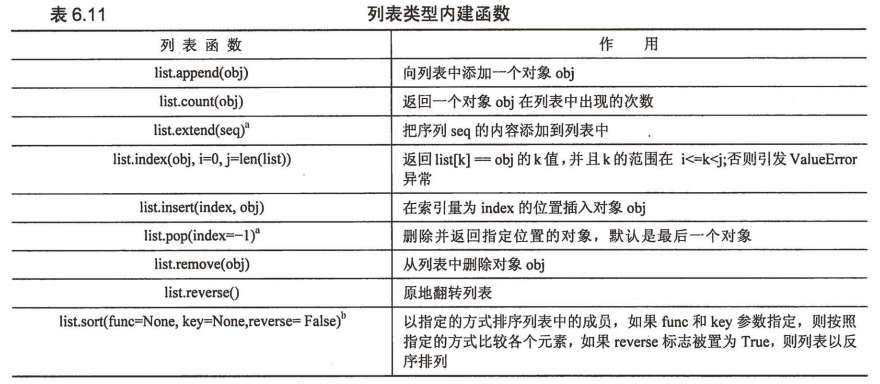
列表
列表类型的内建函数一览表:
元组
元祖的一些特有特性:
1 不可改变,但不是完全不可改变,当元祖里有可变类型的内容时(如列表),则可变类型可变(列表可以改变)。
2 单元素元祖,用逗号(,)来实现
>>> ('xyz') #这样创建的是字符串而不是元组
'xyz'
>>> ('xyz',) #正确创建单元素元祖的方法
('xyz',)
一些其他
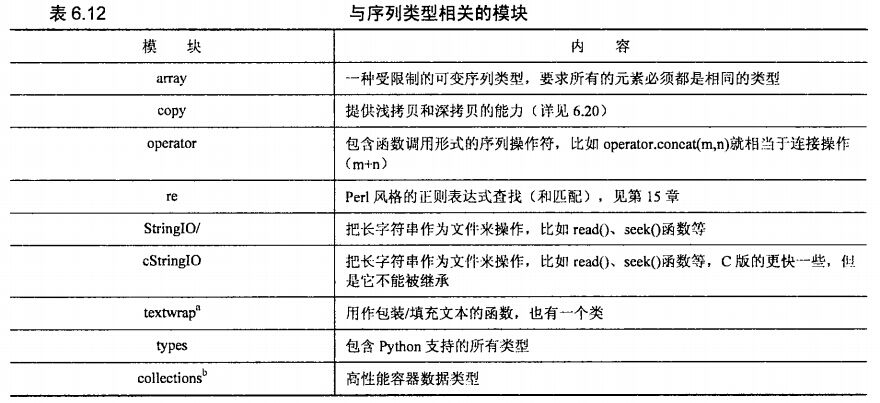
一、与序列类型相关的模块
与序列类型相关的模块一览表:
二、拷贝相关
序列类型对象的默认类型拷贝是浅拷贝,一般是以以下几种方式实施(1)完全切片操作[:];(2)利用工厂函数,比如list(),dict()等;(3)使用copy模块的copy函数。
如果想实现深拷贝,需要copy.deepcopy()函数。
小结
上述部分是对《Python核心编程》一书中序列:字符串、列表和元组一章的读书简记,供快速参考查询。
参考文献
[1] Python核心编程 第二版. Wesley J.Chun。
[2] 你不知道的字符集和编码



