
写在前面
最近计划在北京买房,谁想房价开始疯长,链家的房价等数据分析只给了一小部分,远远不能满足自己的需求。于是晚上花了几个小时的时间写了个爬虫,爬下了北京所有的小区信息及北京的所有历史成交记录。将代码贴在此以分享给需要的人。
干货
# -*- coding: utf-8 -*-
"""
@author: 冰蓝
@site: http://lanbing510.info
"""
import re
import urllib2
import sqlite3
import random
import threading
from bs4 import BeautifulSoup
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
#登录,不登录不能爬取三个月之内的数据
import LianJiaLogIn
#Some User Agents
hds=[{'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'},\
{'User-Agent':'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.12 Safari/535.11'},\
{'User-Agent':'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Trident/6.0)'},\
{'User-Agent':'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:34.0) Gecko/20100101 Firefox/34.0'},\
{'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/44.0.2403.89 Chrome/44.0.2403.89 Safari/537.36'},\
{'User-Agent':'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'},\
{'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'},\
{'User-Agent':'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0'},\
{'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1'},\
{'User-Agent':'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1'},\
{'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11'},\
{'User-Agent':'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11'},\
{'User-Agent':'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11'}]
#北京区域列表
regions=[u"东城",u"西城",u"朝阳",u"海淀",u"丰台",u"石景山","通州",u"昌平",u"大兴",u"亦庄开发区",u"顺义",u"房山",u"门头沟",u"平谷",u"怀柔",u"密云",u"延庆",u"燕郊"]
lock = threading.Lock()
class SQLiteWraper(object):
"""
数据库的一个小封装,更好的处理多线程写入
"""
def __init__(self,path,command='',*args,**kwargs):
self.lock = threading.RLock() #锁
self.path = path #数据库连接参数
if command!='':
conn=self.get_conn()
cu=conn.cursor()
cu.execute(command)
def get_conn(self):
conn = sqlite3.connect(self.path)#,check_same_thread=False)
conn.text_factory=str
return conn
def conn_close(self,conn=None):
conn.close()
def conn_trans(func):
def connection(self,*args,**kwargs):
self.lock.acquire()
conn = self.get_conn()
kwargs['conn'] = conn
rs = func(self,*args,**kwargs)
self.conn_close(conn)
self.lock.release()
return rs
return connection
@conn_trans
def execute(self,command,method_flag=0,conn=None):
cu = conn.cursor()
try:
if not method_flag:
cu.execute(command)
else:
cu.execute(command[0],command[1])
conn.commit()
except sqlite3.IntegrityError,e:
#print e
return -1
except Exception, e:
print e
return -2
return 0
@conn_trans
def fetchall(self,command="select name from xiaoqu",conn=None):
cu=conn.cursor()
lists=[]
try:
cu.execute(command)
lists=cu.fetchall()
except Exception,e:
print e
pass
return lists
def gen_xiaoqu_insert_command(info_dict):
"""
生成小区数据库插入命令
"""
info_list=[u'小区名称',u'大区域',u'小区域',u'小区户型',u'建造时间']
t=[]
for il in info_list:
if il in info_dict:
t.append(info_dict[il])
else:
t.append('')
t=tuple(t)
command=(r"insert into xiaoqu values(?,?,?,?,?)",t)
return command
def gen_chengjiao_insert_command(info_dict):
"""
生成成交记录数据库插入命令
"""
info_list=[u'链接',u'小区名称',u'户型',u'面积',u'朝向',u'楼层',u'建造时间',u'签约时间',u'签约单价',u'签约总价',u'房产类型',u'学区',u'地铁']
t=[]
for il in info_list:
if il in info_dict:
t.append(info_dict[il])
else:
t.append('')
t=tuple(t)
command=(r"insert into chengjiao values(?,?,?,?,?,?,?,?,?,?,?,?,?)",t)
return command
def xiaoqu_spider(db_xq,url_page=u"http://bj.lianjia.com/xiaoqu/pg1rs%E6%98%8C%E5%B9%B3/"):
"""
爬取页面链接中的小区信息
"""
try:
req = urllib2.Request(url_page,headers=hds[random.randint(0,len(hds)-1)])
source_code = urllib2.urlopen(req,timeout=10).read()
plain_text=unicode(source_code)#,errors='ignore')
soup = BeautifulSoup(plain_text)
except (urllib2.HTTPError, urllib2.URLError), e:
print e
exit(-1)
except Exception,e:
print e
exit(-1)
xiaoqu_list=soup.findAll('div',{'class':'info-panel'})
for xq in xiaoqu_list:
info_dict={}
info_dict.update({u'小区名称':xq.find('a').text})
content=unicode(xq.find('div',{'class':'con'}).renderContents().strip())
info=re.match(r".+>(.+)</a>.+>(.+)</a>.+</span>(.+)<span>.+</span>(.+)",content)
if info:
info=info.groups()
info_dict.update({u'大区域':info[0]})
info_dict.update({u'小区域':info[1]})
info_dict.update({u'小区户型':info[2]})
info_dict.update({u'建造时间':info[3][:4]})
command=gen_xiaoqu_insert_command(info_dict)
db_xq.execute(command,1)
def do_xiaoqu_spider(db_xq,region=u"昌平"):
"""
爬取大区域中的所有小区信息
"""
url=u"http://bj.lianjia.com/xiaoqu/rs"+region+"/"
try:
req = urllib2.Request(url,headers=hds[random.randint(0,len(hds)-1)])
source_code = urllib2.urlopen(req,timeout=5).read()
plain_text=unicode(source_code)#,errors='ignore')
soup = BeautifulSoup(plain_text)
except (urllib2.HTTPError, urllib2.URLError), e:
print e
return
except Exception,e:
print e
return
d="d="+soup.find('div',{'class':'page-box house-lst-page-box'}).get('page-data')
exec(d)
total_pages=d['totalPage']
threads=[]
for i in range(total_pages):
url_page=u"http://bj.lianjia.com/xiaoqu/pg%drs%s/" % (i+1,region)
t=threading.Thread(target=xiaoqu_spider,args=(db_xq,url_page))
threads.append(t)
for t in threads:
t.start()
for t in threads:
t.join()
print u"爬下了 %s 区全部的小区信息" % region
def chengjiao_spider(db_cj,url_page=u"http://bj.lianjia.com/chengjiao/pg1rs%E5%86%A0%E5%BA%AD%E5%9B%AD"):
"""
爬取页面链接中的成交记录
"""
try:
req = urllib2.Request(url_page,headers=hds[random.randint(0,len(hds)-1)])
source_code = urllib2.urlopen(req,timeout=10).read()
plain_text=unicode(source_code)#,errors='ignore')
soup = BeautifulSoup(plain_text)
except (urllib2.HTTPError, urllib2.URLError), e:
print e
exception_write('chengjiao_spider',url_page)
return
except Exception,e:
print e
exception_write('chengjiao_spider',url_page)
return
cj_list=soup.findAll('div',{'class':'info-panel'})
for cj in cj_list:
info_dict={}
href=cj.find('a')
if not href:
continue
info_dict.update({u'链接':href.attrs['href']})
content=cj.find('h2').text.split()
if content:
info_dict.update({u'小区名称':content[0]})
info_dict.update({u'户型':content[1]})
info_dict.update({u'面积':content[2]})
content=unicode(cj.find('div',{'class':'con'}).renderContents().strip())
content=content.split('/')
if content:
info_dict.update({u'朝向':content[0].strip()})
info_dict.update({u'楼层':content[1].strip()})
if len(content)>=3:
content[2]=content[2].strip();
info_dict.update({u'建造时间':content[2][:4]})
content=cj.findAll('div',{'class':'div-cun'})
if content:
info_dict.update({u'签约时间':content[0].text})
info_dict.update({u'签约单价':content[1].text})
info_dict.update({u'签约总价':content[2].text})
content=cj.find('div',{'class':'introduce'}).text.strip().split()
if content:
for c in content:
if c.find(u'满')!=-1:
info_dict.update({u'房产类型':c})
elif c.find(u'学')!=-1:
info_dict.update({u'学区':c})
elif c.find(u'距')!=-1:
info_dict.update({u'地铁':c})
command=gen_chengjiao_insert_command(info_dict)
db_cj.execute(command,1)
def xiaoqu_chengjiao_spider(db_cj,xq_name=u"冠庭园"):
"""
爬取小区成交记录
"""
url=u"http://bj.lianjia.com/chengjiao/rs"+urllib2.quote(xq_name)+"/"
try:
req = urllib2.Request(url,headers=hds[random.randint(0,len(hds)-1)])
source_code = urllib2.urlopen(req,timeout=10).read()
plain_text=unicode(source_code)#,errors='ignore')
soup = BeautifulSoup(plain_text)
except (urllib2.HTTPError, urllib2.URLError), e:
print e
exception_write('xiaoqu_chengjiao_spider',xq_name)
return
except Exception,e:
print e
exception_write('xiaoqu_chengjiao_spider',xq_name)
return
content=soup.find('div',{'class':'page-box house-lst-page-box'})
total_pages=0
if content:
d="d="+content.get('page-data')
exec(d)
total_pages=d['totalPage']
threads=[]
for i in range(total_pages):
url_page=u"http://bj.lianjia.com/chengjiao/pg%drs%s/" % (i+1,urllib2.quote(xq_name))
t=threading.Thread(target=chengjiao_spider,args=(db_cj,url_page))
threads.append(t)
for t in threads:
t.start()
for t in threads:
t.join()
def do_xiaoqu_chengjiao_spider(db_xq,db_cj):
"""
批量爬取小区成交记录
"""
count=0
xq_list=db_xq.fetchall()
for xq in xq_list:
xiaoqu_chengjiao_spider(db_cj,xq[0])
count+=1
print 'have spidered %d xiaoqu' % count
print 'done'
def exception_write(fun_name,url):
"""
写入异常信息到日志
"""
lock.acquire()
f = open('log.txt','a')
line="%s %s\n" % (fun_name,url)
f.write(line)
f.close()
lock.release()
def exception_read():
"""
从日志中读取异常信息
"""
lock.acquire()
f=open('log.txt','r')
lines=f.readlines()
f.close()
f=open('log.txt','w')
f.truncate()
f.close()
lock.release()
return lines
def exception_spider(db_cj):
"""
重新爬取爬取异常的链接
"""
count=0
excep_list=exception_read()
while excep_list:
for excep in excep_list:
excep=excep.strip()
if excep=="":
continue
excep_name,url=excep.split(" ",1)
if excep_name=="chengjiao_spider":
chengjiao_spider(db_cj,url)
count+=1
elif excep_name=="xiaoqu_chengjiao_spider":
xiaoqu_chengjiao_spider(db_cj,url)
count+=1
else:
print "wrong format"
print "have spidered %d exception url" % count
excep_list=exception_read()
print 'all done ^_^'
if __name__=="__main__":
command="create table if not exists xiaoqu (name TEXT primary key UNIQUE, regionb TEXT, regions TEXT, style TEXT, year TEXT)"
db_xq=SQLiteWraper('lianjia-xq.db',command)
command="create table if not exists chengjiao (href TEXT primary key UNIQUE, name TEXT, style TEXT, area TEXT, orientation TEXT, floor TEXT, year TEXT, sign_time TEXT, unit_price TEXT, total_price TEXT,fangchan_class TEXT, school TEXT, subway TEXT)"
db_cj=SQLiteWraper('lianjia-cj.db',command)
#爬下所有的小区信息
for region in regions:
do_xiaoqu_spider(db_xq,region)
#爬下所有小区里的成交信息
do_xiaoqu_chengjiao_spider(db_xq,db_cj)
#重新爬取爬取异常的链接
exception_spider(db_cj)
部分截图
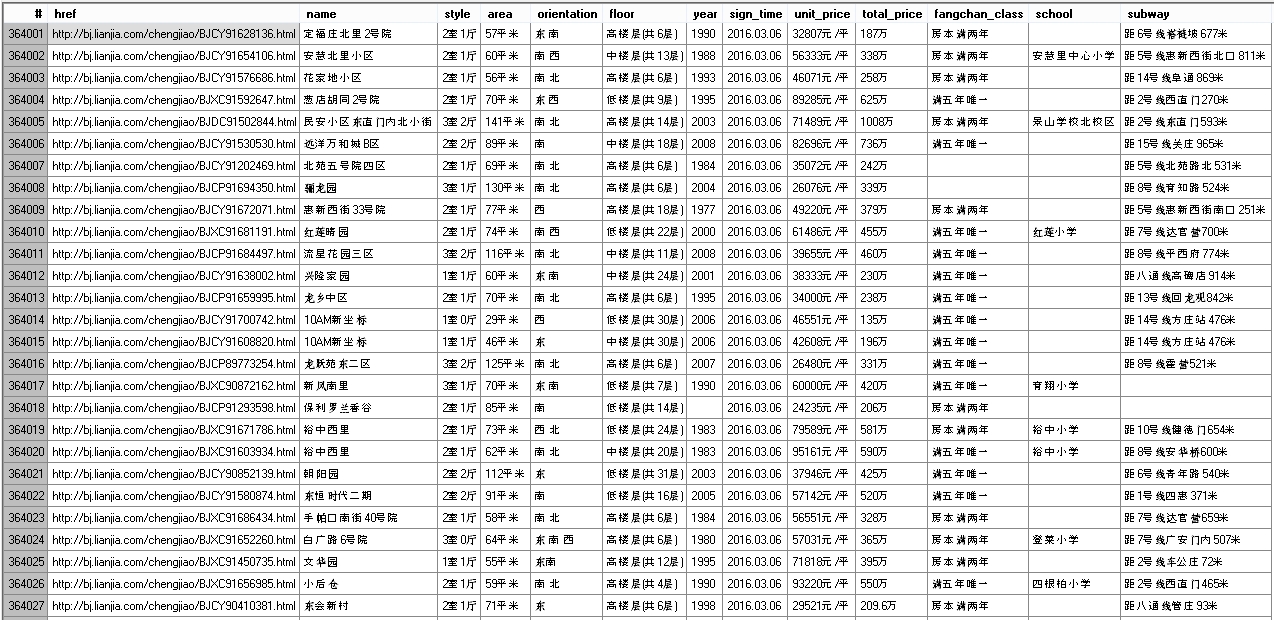
小注
链家成交记录页面只提供了100个页面的成交记录,于是上述爬虫采用的曲线爬取,先爬每个小区,然后爬每个小区的成交记录,如此来得到所有的历史成交记录。哈哈,拿到所有的数据后就可以任性的进行各种数据分析了!信息就是宝贵的财富资源。PS,链家对爬虫还是很友好的,代理IP都没用就爬下了所有的四十多万条历史成交记录。现在已经买了房,北京的全部历史成交记录数据(2002-2016年3月份)已在微博上分享下载链接,后期相应的更新也敬请关注微博。
参考
[1] 链家的模拟登录



