
写在前面
GPU高性能编程CUDA实战对于没有接触过GPU编程的人是非常不错的一本入门书,脉络清晰,例子由浅入深。下文是一些笔记,代码占了很大部分(代码很好的解释了用法),方便用到的时候查阅复习。
第1篇 CUDA C简介
本篇主要对CUDA C编程进行了简介,介绍了如何查询支持CUDA的设备的信息。
代码Enum GPU主要涉及到了设备属性的查询。
#include "../common/book.h"
int main( void ) {
cudaDeviceProp prop;
int count;
HANDLE_ERROR( cudaGetDeviceCount( &count ) );
for (int i=0; i< count; i++) {
HANDLE_ERROR( cudaGetDeviceProperties( &prop, i ) );
printf( " --- General Information for device %d ---\n", i );
printf( "Name: %s\n", prop.name );
printf( "Compute capability: %d.%d\n", prop.major, prop.minor );
printf( "Clock rate: %d\n", prop.clockRate );
printf( "Device copy overlap: " );
if (prop.deviceOverlap)
printf( "Enabled\n" );
else
printf( "Disabled\n");
printf( "Kernel execution timeout : " );
if (prop.kernelExecTimeoutEnabled)
printf( "Enabled\n" );
else
printf( "Disabled\n" );
printf( " --- Memory Information for device %d ---\n", i );
printf( "Total global mem: %ld\n", prop.totalGlobalMem );
printf( "Total constant Mem: %ld\n", prop.totalConstMem );
printf( "Max mem pitch: %ld\n", prop.memPitch );
printf( "Texture Alignment: %ld\n", prop.textureAlignment );
printf( " --- MP Information for device %d ---\n", i );
printf( "Multiprocessor count: %d\n",
prop.multiProcessorCount );
printf( "Shared mem per mp: %ld\n", prop.sharedMemPerBlock );
printf( "Registers per mp: %d\n", prop.regsPerBlock );
printf( "Threads in warp: %d\n", prop.warpSize );
printf( "Max threads per block: %d\n",
prop.maxThreadsPerBlock );
printf( "Max thread dimensions: (%d, %d, %d)\n",
prop.maxThreadsDim[0], prop.maxThreadsDim[1],
prop.maxThreadsDim[2] );
printf( "Max grid dimensions: (%d, %d, %d)\n",
prop.maxGridSize[0], prop.maxGridSize[1],
prop.maxGridSize[2] );
printf( "\n" );
}
}
第2篇 CUDA C并行编程
本篇主要介绍了如何使用CUDA C编写并行代码。
代码Add Loop Long实现了使用GPU计算向量加法。其中核函数add<<<128,1>>>中第一个参数表示设备在执行核函数时是用的并行线程块的数量。其中blockIdx代表线程块的索引。将add核函数声明为__global__函数,从而可从主机上调用并在设备上运行。
#include "../common/book.h"
#define N (32 * 1024)
__global__ void add( int *a, int *b, int *c ) {
int tid = blockIdx.x;
while (tid < N) {
c[tid] = a[tid] + b[tid];
tid += gridDim.x;
}
}
int main( void ) {
int *a, *b, *c;
int *dev_a, *dev_b, *dev_c;
// allocate the memory on the CPU
a = (int*)malloc( N * sizeof(int) );
b = (int*)malloc( N * sizeof(int) );
c = (int*)malloc( N * sizeof(int) );
// allocate the memory on the GPU
HANDLE_ERROR( cudaMalloc( (void**)&dev_a, N * sizeof(int) ) );
HANDLE_ERROR( cudaMalloc( (void**)&dev_b, N * sizeof(int) ) );
HANDLE_ERROR( cudaMalloc( (void**)&dev_c, N * sizeof(int) ) );
// fill the arrays 'a' and 'b' on the CPU
for (int i=0; i<N; i++) {
a[i] = i;
b[i] = 2 * i;
}
// copy the arrays 'a' and 'b' to the GPU
HANDLE_ERROR( cudaMemcpy( dev_a, a, N * sizeof(int),
cudaMemcpyHostToDevice ) );
HANDLE_ERROR( cudaMemcpy( dev_b, b, N * sizeof(int),
cudaMemcpyHostToDevice ) );
add<<<128,1>>>( dev_a, dev_b, dev_c );
// copy the array 'c' back from the GPU to the CPU
HANDLE_ERROR( cudaMemcpy( c, dev_c, N * sizeof(int),
cudaMemcpyDeviceToHost ) );
// verify that the GPU did the work we requested
bool success = true;
for (int i=0; i<N; i++) {
if ((a[i] + b[i]) != c[i]) {
printf( "Error: %d + %d != %d\n", a[i], b[i], c[i] );
success = false;
}
}
if (success) printf( "We did it!\n" );
// free the memory we allocated on the GPU
HANDLE_ERROR( cudaFree( dev_a ) );
HANDLE_ERROR( cudaFree( dev_b ) );
HANDLE_ERROR( cudaFree( dev_c ) );
// free the memory we allocated on the CPU
free( a );
free( b );
free( c );
return 0;
}
代码Julia使用GPU实现了生成Julia集的算法。其中__device__声明的函数,表示将在GPU而不是主机上运行,只能从其他__device__函数或者重__global__函数中调用它们。
#include "../common/book.h"
#include "../common/cpu_bitmap.h"
#define DIM 1000
struct cuComplex {
float r;
float i;
cuComplex( float a, float b ) : r(a), i(b) {}
__device__ float magnitude2( void ) {
return r * r + i * i;
}
__device__ cuComplex operator*(const cuComplex& a) {
return cuComplex(r*a.r - i*a.i, i*a.r + r*a.i);
}
__device__ cuComplex operator+(const cuComplex& a) {
return cuComplex(r+a.r, i+a.i);
}
};
__device__ int julia( int x, int y ) {
const float scale = 1.5;
float jx = scale * (float)(DIM/2 - x)/(DIM/2);
float jy = scale * (float)(DIM/2 - y)/(DIM/2);
cuComplex c(-0.8, 0.156);
cuComplex a(jx, jy);
int i = 0;
for (i=0; i<200; i++) {
a = a * a + c;
if (a.magnitude2() > 1000)
return 0;
}
return 1;
}
__global__ void kernel( unsigned char *ptr ) {
// map from blockIdx to pixel position
int x = blockIdx.x;
int y = blockIdx.y;
int offset = x + y * gridDim.x;
// now calculate the value at that position
int juliaValue = julia( x, y );
ptr[offset*4 + 0] = 255 * juliaValue;
ptr[offset*4 + 1] = 0;
ptr[offset*4 + 2] = 0;
ptr[offset*4 + 3] = 255;
}
// globals needed by the update routine
struct DataBlock {
unsigned char *dev_bitmap;
};
int main( void ) {
DataBlock data;
CPUBitmap bitmap( DIM, DIM, &data );
unsigned char *dev_bitmap;
HANDLE_ERROR( cudaMalloc( (void**)&dev_bitmap, bitmap.image_size() ) );
data.dev_bitmap = dev_bitmap;
dim3 grid(DIM,DIM);
kernel<<<grid,1>>>( dev_bitmap );
HANDLE_ERROR( cudaMemcpy( bitmap.get_ptr(), dev_bitmap,
bitmap.image_size(),
cudaMemcpyDeviceToHost ) );
HANDLE_ERROR( cudaFree( dev_bitmap ) );
bitmap.display_and_exit();
}
第3篇 线程协作
本篇主要介绍CUDA中的线程、不同线程间的通信机制、并行执行线程的同步机制。
代码Add Loop Long Blocks中,核函数add<<<128,128>>>第一个参数表示使用128个线程块,第二个参数表示每个线程块中创建128个线程数量。在add核函数中,blockDim是一个常数,保存的是线程块中每一维的线程数量;gridDim保存了一个类似的值,即在线程格中每一维的线程块数量。gridDim是二维的,blockDim实际上是三维的。
代码Ripple使用GPU实现了波纹效果。代码中使用了二维的线程块和线程数组。
#include "../common/book.h"
#define N (33 * 1024)
__global__ void add( int *a, int *b, int *c ) {
int tid = threadIdx.x + blockIdx.x * blockDim.x;
while (tid < N) {
c[tid] = a[tid] + b[tid];
tid += blockDim.x * gridDim.x;
}
}
int main( void ) {
int *a, *b, *c;
int *dev_a, *dev_b, *dev_c;
// allocate the memory on the CPU
a = (int*)malloc( N * sizeof(int) );
b = (int*)malloc( N * sizeof(int) );
c = (int*)malloc( N * sizeof(int) );
// allocate the memory on the GPU
HANDLE_ERROR( cudaMalloc( (void**)&dev_a, N * sizeof(int) ) );
HANDLE_ERROR( cudaMalloc( (void**)&dev_b, N * sizeof(int) ) );
HANDLE_ERROR( cudaMalloc( (void**)&dev_c, N * sizeof(int) ) );
// fill the arrays 'a' and 'b' on the CPU
for (int i=0; i<N; i++) {
a[i] = i;
b[i] = 2 * i;
}
// copy the arrays 'a' and 'b' to the GPU
HANDLE_ERROR( cudaMemcpy( dev_a, a, N * sizeof(int),
cudaMemcpyHostToDevice ) );
HANDLE_ERROR( cudaMemcpy( dev_b, b, N * sizeof(int),
cudaMemcpyHostToDevice ) );
add<<<128,128>>>( dev_a, dev_b, dev_c );
// copy the array 'c' back from the GPU to the CPU
HANDLE_ERROR( cudaMemcpy( c, dev_c, N * sizeof(int),
cudaMemcpyDeviceToHost ) );
// verify that the GPU did the work we requested
bool success = true;
for (int i=0; i<N; i++) {
if ((a[i] + b[i]) != c[i]) {
printf( "Error: %d + %d != %d\n", a[i], b[i], c[i] );
success = false;
}
}
if (success) printf( "We did it!\n" );
// free the memory we allocated on the GPU
HANDLE_ERROR( cudaFree( dev_a ) );
HANDLE_ERROR( cudaFree( dev_b ) );
HANDLE_ERROR( cudaFree( dev_c ) );
// free the memory we allocated on the CPU
free( a );
free( b );
free( c );
return 0;
}
#include "cuda.h"
#include "../common/book.h"
#include "../common/cpu_anim.h"
#define DIM 1024
#define PI 3.1415926535897932f
__global__ void kernel( unsigned char *ptr, int ticks ) {
// map from threadIdx/BlockIdx to pixel position
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
// now calculate the value at that position
float fx = x - DIM/2;
float fy = y - DIM/2;
float d = sqrtf( fx * fx + fy * fy );
unsigned char grey = (unsigned char)(128.0f + 127.0f *
cos(d/10.0f - ticks/7.0f) /
(d/10.0f + 1.0f));
ptr[offset*4 + 0] = grey;
ptr[offset*4 + 1] = grey;
ptr[offset*4 + 2] = grey;
ptr[offset*4 + 3] = 255;
}
struct DataBlock {
unsigned char *dev_bitmap;
CPUAnimBitmap *bitmap;
};
void generate_frame( DataBlock *d, int ticks ) {
dim3 blocks(DIM/16,DIM/16);
dim3 threads(16,16);
kernel<<<blocks,threads>>>( d->dev_bitmap, ticks );
HANDLE_ERROR( cudaMemcpy( d->bitmap->get_ptr(),
d->dev_bitmap,
d->bitmap->image_size(),
cudaMemcpyDeviceToHost ) );
}
// clean up memory allocated on the GPU
void cleanup( DataBlock *d ) {
HANDLE_ERROR( cudaFree( d->dev_bitmap ) );
}
int main( void ) {
DataBlock data;
CPUAnimBitmap bitmap( DIM, DIM, &data );
data.bitmap = &bitmap;
HANDLE_ERROR( cudaMalloc( (void**)&data.dev_bitmap,
bitmap.image_size() ) );
bitmap.anim_and_exit( (void (*)(void*,int))generate_frame,
(void (*)(void*))cleanup );
}
代码Dot实现了矢量的点积运算。展示了共享内存的使用。编写代码时,将CUDA C的关键字__share__添加到变量声明中,将会使这个变量驻留在共享内存中,这样线程块中的每个线程都共享这块内存,但线程却无法看到也不能修改其他线程块的变量副本。程序中,共享内存缓存中的偏移就等于线程索引,线程块索引与这个偏移无关,因为每个线程块都拥有该共享内存的私有副本。
同时还要注意到对线程块中的线程进行同步:__syncthreads()。这个函数调用将确保线程块中的每个线程都执行完__syncthreads()前面的语句后,才会执行下一条语句。还需注意,如果将__synctheads()调用移入到if()线程块中,那么任何cacheIndex大于或等于i的线程都永远不能执行__syncthreads()。这将使处理器挂起。
#include "../common/book.h"
#define imin(a,b) (a<b?a:b)
const int N = 33 * 1024;
const int threadsPerBlock = 256;
const int blocksPerGrid =
imin( 32, (N+threadsPerBlock-1) / threadsPerBlock );
__global__ void dot( float *a, float *b, float *c ) {
__shared__ float cache[threadsPerBlock];
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int cacheIndex = threadIdx.x;
float temp = 0;
while (tid < N) {
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
}
// set the cache values
cache[cacheIndex] = temp;
// synchronize threads in this block
__syncthreads();
// for reductions, threadsPerBlock must be a power of 2
// because of the following code
int i = blockDim.x/2;
while (i != 0) {
if (cacheIndex < i)
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads();
i /= 2;
}
if (cacheIndex == 0)
c[blockIdx.x] = cache[0];
}
int main( void ) {
float *a, *b, c, *partial_c;
float *dev_a, *dev_b, *dev_partial_c;
// allocate memory on the cpu side
a = (float*)malloc( N*sizeof(float) );
b = (float*)malloc( N*sizeof(float) );
partial_c = (float*)malloc( blocksPerGrid*sizeof(float) );
// allocate the memory on the GPU
HANDLE_ERROR( cudaMalloc( (void**)&dev_a,
N*sizeof(float) ) );
HANDLE_ERROR( cudaMalloc( (void**)&dev_b,
N*sizeof(float) ) );
HANDLE_ERROR( cudaMalloc( (void**)&dev_partial_c,
blocksPerGrid*sizeof(float) ) );
// fill in the host memory with data
for (int i=0; i<N; i++) {
a[i] = i;
b[i] = i*2;
}
// copy the arrays 'a' and 'b' to the GPU
HANDLE_ERROR( cudaMemcpy( dev_a, a, N*sizeof(float),
cudaMemcpyHostToDevice ) );
HANDLE_ERROR( cudaMemcpy( dev_b, b, N*sizeof(float),
cudaMemcpyHostToDevice ) );
dot<<<blocksPerGrid,threadsPerBlock>>>( dev_a, dev_b,
dev_partial_c );
// copy the array 'c' back from the GPU to the CPU
HANDLE_ERROR( cudaMemcpy( partial_c, dev_partial_c,
blocksPerGrid*sizeof(float),
cudaMemcpyDeviceToHost ) );
// finish up on the CPU side
c = 0;
for (int i=0; i<blocksPerGrid; i++) {
c += partial_c[i];
}
#define sum_squares(x) (x*(x+1)*(2*x+1)/6)
printf( "Does GPU value %.6g = %.6g?\n", c,
2 * sum_squares( (float)(N - 1) ) );
// free memory on the gpu side
HANDLE_ERROR( cudaFree( dev_a ) );
HANDLE_ERROR( cudaFree( dev_b ) );
HANDLE_ERROR( cudaFree( dev_partial_c ) );
// free memory on the cpu side
free( a );
free( b );
free( partial_c );
}
第4篇 常量内存与事件
本篇将介绍如何在CUDA C中使用常量内存、常量内存的特性及如何使用CUDA事件来测量应用程序的性能。
代码Ray展示了如何使用常量内存。常量内存的声明方法与共享内存类似,在变量前加上__constant__修饰符即可。__constant__将把变量的访问限制为只读。在某些情况中,用常量内存来替换全局内存能有效减少内存宽带。其可以节约内存带宽主要有两个原因:1 对常量内存的单次操作可以广播到其他邻近线程,这将节约15次读取操作;2 常量内存的数据将缓存起来,因此对相同地址的连续读操作将不会产生额外的内存通信量。
邻近这个词的含义是什么?首先解释线程束(Wrap)的概念。线程束可以看出是一组线程通过交织而形成的一个整体。在CUDA架构中,线程束是一个包含32个线程的ihe,这个线程集合被编织在一起,并且步调一致(Lockstep)的形式执行。在程序中的每一行,线程束中的每个线程都将在不同的数据上执行相同的指令。
当处理常量内存时,NVIDIA硬件将把单次内存读取操作广播到每个半线程束。如果在半线程束中的每个线程都从常量内存的相同地址上读取数据,那么GPU只会产生一次请求并在随后将数据广播到每个线程。只有当16个线程每次都只需要相同的读取求情时,才值得将这个读取操作广播到16个线程。然而,如果半线程束中所有16个线程需要访问常量内存中不同的数据,那么这个16个读取操作将被串行化,从而需要16倍的时间发出请求。但如果从全局内存中读取,这些请求会同时发出。这种情况中,从常量内存读取就慢雨从全局内存中读取。
代码Ray同时展示了如何使用CUDA事件进行计时。
#include "cuda.h"
#include "../common/book.h"
#include "../common/cpu_bitmap.h"
#define DIM 1024
#define rnd( x ) (x * rand() / RAND_MAX)
#define INF 2e10f
struct Sphere {
float r,b,g;
float radius;
float x,y,z;
__device__ float hit( float ox, float oy, float *n ) {
float dx = ox - x;
float dy = oy - y;
if (dx*dx + dy*dy < radius*radius) {
float dz = sqrtf( radius*radius - dx*dx - dy*dy );
*n = dz / sqrtf( radius * radius );
return dz + z;
}
return -INF;
}
};
#define SPHERES 20
__constant__ Sphere s[SPHERES];
__global__ void kernel( unsigned char *ptr ) {
// map from threadIdx/BlockIdx to pixel position
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float ox = (x - DIM/2);
float oy = (y - DIM/2);
float r=0, g=0, b=0;
float maxz = -INF;
for(int i=0; i<SPHERES; i++) {
float n;
float t = s[i].hit( ox, oy, &n );
if (t > maxz) {
float fscale = n;
r = s[i].r * fscale;
g = s[i].g * fscale;
b = s[i].b * fscale;
maxz = t;
}
}
ptr[offset*4 + 0] = (int)(r * 255);
ptr[offset*4 + 1] = (int)(g * 255);
ptr[offset*4 + 2] = (int)(b * 255);
ptr[offset*4 + 3] = 255;
}
// globals needed by the update routine
struct DataBlock {
unsigned char *dev_bitmap;
};
int main( void ) {
DataBlock data;
// capture the start time
cudaEvent_t start, stop;
HANDLE_ERROR( cudaEventCreate( &start ) );
HANDLE_ERROR( cudaEventCreate( &stop ) );
HANDLE_ERROR( cudaEventRecord( start, 0 ) );
CPUBitmap bitmap( DIM, DIM, &data );
unsigned char *dev_bitmap;
// allocate memory on the GPU for the output bitmap
HANDLE_ERROR( cudaMalloc( (void**)&dev_bitmap,
bitmap.image_size() ) );
// allocate temp memory, initialize it, copy to constant
// memory on the GPU, then free our temp memory
Sphere *temp_s = (Sphere*)malloc( sizeof(Sphere) * SPHERES );
for (int i=0; i<SPHERES; i++) {
temp_s[i].r = rnd( 1.0f );
temp_s[i].g = rnd( 1.0f );
temp_s[i].b = rnd( 1.0f );
temp_s[i].x = rnd( 1000.0f ) - 500;
temp_s[i].y = rnd( 1000.0f ) - 500;
temp_s[i].z = rnd( 1000.0f ) - 500;
temp_s[i].radius = rnd( 100.0f ) + 20;
}
HANDLE_ERROR( cudaMemcpyToSymbol( s, temp_s,
sizeof(Sphere) * SPHERES) );
free( temp_s );
// generate a bitmap from our sphere data
dim3 grids(DIM/16,DIM/16);
dim3 threads(16,16);
kernel<<<grids,threads>>>( dev_bitmap );
// copy our bitmap back from the GPU for display
HANDLE_ERROR( cudaMemcpy( bitmap.get_ptr(), dev_bitmap,
bitmap.image_size(),
cudaMemcpyDeviceToHost ) );
// get stop time, and display the timing results
HANDLE_ERROR( cudaEventRecord( stop, 0 ) );
HANDLE_ERROR( cudaEventSynchronize( stop ) );
float elapsedTime;
HANDLE_ERROR( cudaEventElapsedTime( &elapsedTime,
start, stop ) );
printf( "Time to generate: %3.1f ms\n", elapsedTime );
HANDLE_ERROR( cudaEventDestroy( start ) );
HANDLE_ERROR( cudaEventDestroy( stop ) );
HANDLE_ERROR( cudaFree( dev_bitmap ) );
// display
bitmap.display_and_exit();
}
第5篇 纹理内存
本篇主要介绍纹理内存。和常量内存一样,纹理内存是另一种类型的只读内存,在特定的访问模式中,纹理内存同样能够提升性能并减少内存流量。纹理缓存是专门为那些在内存访问模式中存在大量空间局部性的图形应用程序而设计的。
代码Heat2D对热传导进行了简单的模拟,展示了二维纹理内存的使用。使用纹理内存时,首先需要对数据声明为texture类型的引用:texture<类型, 维度> variable,然后需要通过cudaBindTexture()将这些变量绑定到内存缓冲区来告诉CUDA:1 我们希望将指定的缓冲区作为纹理来使用;2 我们希望将纹理引用作为纹理的名字。
#include "cuda.h"
#include "../common/book.h"
#include "../common/cpu_anim.h"
#define DIM 1024
#define PI 3.1415926535897932f
#define MAX_TEMP 1.0f
#define MIN_TEMP 0.0001f
#define SPEED 0.25f
// these exist on the GPU side
texture<float,2> texConstSrc;
texture<float,2> texIn;
texture<float,2> texOut;
__global__ void blend_kernel( float *dst,
bool dstOut ) {
// map from threadIdx/BlockIdx to pixel position
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float t, l, c, r, b;
if (dstOut) {
t = tex2D(texIn,x,y-1);
l = tex2D(texIn,x-1,y);
c = tex2D(texIn,x,y);
r = tex2D(texIn,x+1,y);
b = tex2D(texIn,x,y+1);
} else {
t = tex2D(texOut,x,y-1);
l = tex2D(texOut,x-1,y);
c = tex2D(texOut,x,y);
r = tex2D(texOut,x+1,y);
b = tex2D(texOut,x,y+1);
}
dst[offset] = c + SPEED * (t + b + r + l - 4 * c);
}
__global__ void copy_const_kernel( float *iptr ) {
// map from threadIdx/BlockIdx to pixel position
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float c = tex2D(texConstSrc,x,y);
if (c != 0)
iptr[offset] = c;
}
// globals needed by the update routine
struct DataBlock {
unsigned char *output_bitmap;
float *dev_inSrc;
float *dev_outSrc;
float *dev_constSrc;
CPUAnimBitmap *bitmap;
cudaEvent_t start, stop;
float totalTime;
float frames;
};
void anim_gpu( DataBlock *d, int ticks ) {
HANDLE_ERROR( cudaEventRecord( d->start, 0 ) );
dim3 blocks(DIM/16,DIM/16);
dim3 threads(16,16);
CPUAnimBitmap *bitmap = d->bitmap;
// since tex is global and bound, we have to use a flag to
// select which is in/out per iteration
volatile bool dstOut = true;
for (int i=0; i<90; i++) {
float *in, *out;
if (dstOut) {
in = d->dev_inSrc;
out = d->dev_outSrc;
} else {
out = d->dev_inSrc;
in = d->dev_outSrc;
}
copy_const_kernel<<<blocks,threads>>>( in );
blend_kernel<<<blocks,threads>>>( out, dstOut );
dstOut = !dstOut;
}
float_to_color<<<blocks,threads>>>( d->output_bitmap,
d->dev_inSrc );
HANDLE_ERROR( cudaMemcpy( bitmap->get_ptr(),
d->output_bitmap,
bitmap->image_size(),
cudaMemcpyDeviceToHost ) );
HANDLE_ERROR( cudaEventRecord( d->stop, 0 ) );
HANDLE_ERROR( cudaEventSynchronize( d->stop ) );
float elapsedTime;
HANDLE_ERROR( cudaEventElapsedTime( &elapsedTime,
d->start, d->stop ) );
d->totalTime += elapsedTime;
++d->frames;
printf( "Average Time per frame: %3.1f ms\n",
d->totalTime/d->frames );
}
// clean up memory allocated on the GPU
void anim_exit( DataBlock *d ) {
cudaUnbindTexture( texIn );
cudaUnbindTexture( texOut );
cudaUnbindTexture( texConstSrc );
HANDLE_ERROR( cudaFree( d->dev_inSrc ) );
HANDLE_ERROR( cudaFree( d->dev_outSrc ) );
HANDLE_ERROR( cudaFree( d->dev_constSrc ) );
HANDLE_ERROR( cudaEventDestroy( d->start ) );
HANDLE_ERROR( cudaEventDestroy( d->stop ) );
}
int main( void ) {
DataBlock data;
CPUAnimBitmap bitmap( DIM, DIM, &data );
data.bitmap = &bitmap;
data.totalTime = 0;
data.frames = 0;
HANDLE_ERROR( cudaEventCreate( &data.start ) );
HANDLE_ERROR( cudaEventCreate( &data.stop ) );
int imageSize = bitmap.image_size();
HANDLE_ERROR( cudaMalloc( (void**)&data.output_bitmap,
imageSize ) );
// assume float == 4 chars in size (ie rgba)
HANDLE_ERROR( cudaMalloc( (void**)&data.dev_inSrc,
imageSize ) );
HANDLE_ERROR( cudaMalloc( (void**)&data.dev_outSrc,
imageSize ) );
HANDLE_ERROR( cudaMalloc( (void**)&data.dev_constSrc,
imageSize ) );
cudaChannelFormatDesc desc = cudaCreateChannelDesc<float>();
HANDLE_ERROR( cudaBindTexture2D( NULL, texConstSrc,
data.dev_constSrc,
desc, DIM, DIM,
sizeof(float) * DIM ) );
HANDLE_ERROR( cudaBindTexture2D( NULL, texIn,
data.dev_inSrc,
desc, DIM, DIM,
sizeof(float) * DIM ) );
HANDLE_ERROR( cudaBindTexture2D( NULL, texOut,
data.dev_outSrc,
desc, DIM, DIM,
sizeof(float) * DIM ) );
// initialize the constant data
float *temp = (float*)malloc( imageSize );
for (int i=0; i<DIM*DIM; i++) {
temp[i] = 0;
int x = i % DIM;
int y = i / DIM;
if ((x>300) && (x<600) && (y>310) && (y<601))
temp[i] = MAX_TEMP;
}
temp[DIM*100+100] = (MAX_TEMP + MIN_TEMP)/2;
temp[DIM*700+100] = MIN_TEMP;
temp[DIM*300+300] = MIN_TEMP;
temp[DIM*200+700] = MIN_TEMP;
for (int y=800; y<900; y++) {
for (int x=400; x<500; x++) {
temp[x+y*DIM] = MIN_TEMP;
}
}
HANDLE_ERROR( cudaMemcpy( data.dev_constSrc, temp,
imageSize,
cudaMemcpyHostToDevice ) );
// initialize the input data
for (int y=800; y<DIM; y++) {
for (int x=0; x<200; x++) {
temp[x+y*DIM] = MAX_TEMP;
}
}
HANDLE_ERROR( cudaMemcpy( data.dev_inSrc, temp,
imageSize,
cudaMemcpyHostToDevice ) );
free( temp );
bitmap.anim_and_exit( (void (*)(void*,int))anim_gpu,
(void (*)(void*))anim_exit );
}
第6篇 图形交互操作
本篇主要介绍了CUDA C应用程序与OpenGL和DirectX这两种实时渲染API的交互操作。略。
第7篇 原子性
本篇主要介绍了原子操作性、为什么需要使用它们及如何在CUDA C核函数中执行带有原子操作的运算。
代码Hist GPU Shmem Atomics展示了原子操作性代码的编写,实现了GPU直方图统计。代码中使用atomicAdd实现原子加法操作,通过使用两阶段算法,降低了全局内存的访问竞争程度。
通过一些性能实验,发现当线程块数量为GPU中处理器数量的2倍时(不同于CUDA核心数,1080Ti处理器数为28,每个处理器128个CUDA核,总共3584个CUDA核心),将达到最优性能。
#include "../common/book.h"
#define SIZE (100*1024*1024)
__global__ void histo_kernel( unsigned char *buffer,
long size,
unsigned int *histo ) {
// clear out the accumulation buffer called temp
// since we are launched with 256 threads, it is easy
// to clear that memory with one write per thread
__shared__ unsigned int temp[256];
temp[threadIdx.x] = 0;
__syncthreads();
// calculate the starting index and the offset to the next
// block that each thread will be processing
int i = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
while (i < size) {
atomicAdd( &temp[buffer[i]], 1 );
i += stride;
}
// sync the data from the above writes to shared memory
// then add the shared memory values to the values from
// the other thread blocks using global memory
// atomic adds
// same as before, since we have 256 threads, updating the
// global histogram is just one write per thread!
__syncthreads();
atomicAdd( &(histo[threadIdx.x]), temp[threadIdx.x] );
}
int main( void ) {
unsigned char *buffer =
(unsigned char*)big_random_block( SIZE );
// capture the start time
// starting the timer here so that we include the cost of
// all of the operations on the GPU. if the data were
// already on the GPU and we just timed the kernel
// the timing would drop from 74 ms to 15 ms. Very fast.
cudaEvent_t start, stop;
HANDLE_ERROR( cudaEventCreate( &start ) );
HANDLE_ERROR( cudaEventCreate( &stop ) );
HANDLE_ERROR( cudaEventRecord( start, 0 ) );
// allocate memory on the GPU for the file's data
unsigned char *dev_buffer;
unsigned int *dev_histo;
HANDLE_ERROR( cudaMalloc( (void**)&dev_buffer, SIZE ) );
HANDLE_ERROR( cudaMemcpy( dev_buffer, buffer, SIZE,
cudaMemcpyHostToDevice ) );
HANDLE_ERROR( cudaMalloc( (void**)&dev_histo,
256 * sizeof( int ) ) );
HANDLE_ERROR( cudaMemset( dev_histo, 0,
256 * sizeof( int ) ) );
// kernel launch - 2x the number of mps gave best timing
cudaDeviceProp prop;
HANDLE_ERROR( cudaGetDeviceProperties( &prop, 0 ) );
int blocks = prop.multiProcessorCount;
histo_kernel<<<blocks*2,256>>>( dev_buffer,
SIZE, dev_histo );
unsigned int histo[256];
HANDLE_ERROR( cudaMemcpy( histo, dev_histo,
256 * sizeof( int ),
cudaMemcpyDeviceToHost ) );
// get stop time, and display the timing results
HANDLE_ERROR( cudaEventRecord( stop, 0 ) );
HANDLE_ERROR( cudaEventSynchronize( stop ) );
float elapsedTime;
HANDLE_ERROR( cudaEventElapsedTime( &elapsedTime,
start, stop ) );
printf( "Time to generate: %3.1f ms\n", elapsedTime );
long histoCount = 0;
for (int i=0; i<256; i++) {
histoCount += histo[i];
}
printf( "Histogram Sum: %ld\n", histoCount );
// verify that we have the same counts via CPU
for (int i=0; i<SIZE; i++)
histo[buffer[i]]--;
for (int i=0; i<256; i++) {
if (histo[i] != 0)
printf( "Failure at %d!\n", i );
}
HANDLE_ERROR( cudaEventDestroy( start ) );
HANDLE_ERROR( cudaEventDestroy( stop ) );
cudaFree( dev_histo );
cudaFree( dev_buffer );
free( buffer );
return 0;
}
第8篇 流
本篇主要介绍使用流实现任务并行来加速应用程序。
页锁定主机内存称为固定内存或不可分页内存,操作系统不会对这块内存分页并交换到磁盘上,可确保该内存始终驻留在物理内存中,但使用固定内存时,会失去虚拟内存的所有功能。使用cudaHostAlloc()函数实现分配页锁定的主机内存。
CUDA流在加速应用程序方面起着重要的作用。CUDA流表示一个GPU操作队列,并且该队列中的操作将以指定的顺序执行。
代码Basic Double Stream Correct展示了流的使用。其做的第一件事是选择一个支持设备重叠(Device Overlap)功能的设备。支持设备重叠功能的GPU能够在执行一个CUDA C核函数的同时,在设备和主机间执行复制操作。其中还使用了cudaStreamSynchronize(stream)实现GPU等待流。同时需要注意代码中将操作放入流的顺序,其影响着CUDA驱动程序调度这些操作以及执行的方式。
#include "../common/book.h"
#define N (1024*1024)
#define FULL_DATA_SIZE (N*20)
__global__ void kernel( int *a, int *b, int *c ) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N) {
int idx1 = (idx + 1) % 256;
int idx2 = (idx + 2) % 256;
float as = (a[idx] + a[idx1] + a[idx2]) / 3.0f;
float bs = (b[idx] + b[idx1] + b[idx2]) / 3.0f;
c[idx] = (as + bs) / 2;
}
}
int main( void ) {
cudaDeviceProp prop;
int whichDevice;
HANDLE_ERROR( cudaGetDevice( &whichDevice ) );
HANDLE_ERROR( cudaGetDeviceProperties( &prop, whichDevice ) );
if (!prop.deviceOverlap) {
printf( "Device will not handle overlaps, so no speed up from streams\n" );
return 0;
}
cudaEvent_t start, stop;
float elapsedTime;
cudaStream_t stream0, stream1;
int *host_a, *host_b, *host_c;
int *dev_a0, *dev_b0, *dev_c0;
int *dev_a1, *dev_b1, *dev_c1;
// start the timers
HANDLE_ERROR( cudaEventCreate( &start ) );
HANDLE_ERROR( cudaEventCreate( &stop ) );
// initialize the streams
HANDLE_ERROR( cudaStreamCreate( &stream0 ) );
HANDLE_ERROR( cudaStreamCreate( &stream1 ) );
// allocate the memory on the GPU
HANDLE_ERROR( cudaMalloc( (void**)&dev_a0,
N * sizeof(int) ) );
HANDLE_ERROR( cudaMalloc( (void**)&dev_b0,
N * sizeof(int) ) );
HANDLE_ERROR( cudaMalloc( (void**)&dev_c0,
N * sizeof(int) ) );
HANDLE_ERROR( cudaMalloc( (void**)&dev_a1,
N * sizeof(int) ) );
HANDLE_ERROR( cudaMalloc( (void**)&dev_b1,
N * sizeof(int) ) );
HANDLE_ERROR( cudaMalloc( (void**)&dev_c1,
N * sizeof(int) ) );
// allocate host locked memory, used to stream
HANDLE_ERROR( cudaHostAlloc( (void**)&host_a,
FULL_DATA_SIZE * sizeof(int),
cudaHostAllocDefault ) );
HANDLE_ERROR( cudaHostAlloc( (void**)&host_b,
FULL_DATA_SIZE * sizeof(int),
cudaHostAllocDefault ) );
HANDLE_ERROR( cudaHostAlloc( (void**)&host_c,
FULL_DATA_SIZE * sizeof(int),
cudaHostAllocDefault ) );
for (int i=0; i<FULL_DATA_SIZE; i++) {
host_a[i] = rand();
host_b[i] = rand();
}
HANDLE_ERROR( cudaEventRecord( start, 0 ) );
// now loop over full data, in bite-sized chunks
for (int i=0; i<FULL_DATA_SIZE; i+= N*2) {
// enqueue copies of a in stream0 and stream1
HANDLE_ERROR( cudaMemcpyAsync( dev_a0, host_a+i,
N * sizeof(int),
cudaMemcpyHostToDevice,
stream0 ) );
HANDLE_ERROR( cudaMemcpyAsync( dev_a1, host_a+i+N,
N * sizeof(int),
cudaMemcpyHostToDevice,
stream1 ) );
// enqueue copies of b in stream0 and stream1
HANDLE_ERROR( cudaMemcpyAsync( dev_b0, host_b+i,
N * sizeof(int),
cudaMemcpyHostToDevice,
stream0 ) );
HANDLE_ERROR( cudaMemcpyAsync( dev_b1, host_b+i+N,
N * sizeof(int),
cudaMemcpyHostToDevice,
stream1 ) );
// enqueue kernels in stream0 and stream1
kernel<<<N/256,256,0,stream0>>>( dev_a0, dev_b0, dev_c0 );
kernel<<<N/256,256,0,stream1>>>( dev_a1, dev_b1, dev_c1 );
// enqueue copies of c from device to locked memory
HANDLE_ERROR( cudaMemcpyAsync( host_c+i, dev_c0,
N * sizeof(int),
cudaMemcpyDeviceToHost,
stream0 ) );
HANDLE_ERROR( cudaMemcpyAsync( host_c+i+N, dev_c1,
N * sizeof(int),
cudaMemcpyDeviceToHost,
stream1 ) );
}
HANDLE_ERROR( cudaStreamSynchronize( stream0 ) );
HANDLE_ERROR( cudaStreamSynchronize( stream1 ) );
HANDLE_ERROR( cudaEventRecord( stop, 0 ) );
HANDLE_ERROR( cudaEventSynchronize( stop ) );
HANDLE_ERROR( cudaEventElapsedTime( &elapsedTime,
start, stop ) );
printf( "Time taken: %3.1f ms\n", elapsedTime );
// cleanup the streams and memory
HANDLE_ERROR( cudaFreeHost( host_a ) );
HANDLE_ERROR( cudaFreeHost( host_b ) );
HANDLE_ERROR( cudaFreeHost( host_c ) );
HANDLE_ERROR( cudaFree( dev_a0 ) );
HANDLE_ERROR( cudaFree( dev_b0 ) );
HANDLE_ERROR( cudaFree( dev_c0 ) );
HANDLE_ERROR( cudaFree( dev_a1 ) );
HANDLE_ERROR( cudaFree( dev_b1 ) );
HANDLE_ERROR( cudaFree( dev_c1 ) );
HANDLE_ERROR( cudaStreamDestroy( stream0 ) );
HANDLE_ERROR( cudaStreamDestroy( stream1 ) );
return 0;
}
第9篇 多GPU系统上的CUDA C
本篇主要介绍如何在同一个应用程序中使用多个GPU、如何分配和使用零拷贝内存、如何分配和使用可移动的固定内存。
代码Portable展示了多个GPU的使用,同时涉及到了零拷贝内存、合并式写入内存、可移动的固定内存。
零拷贝内存是指可以在CUDA C核函数中直接访问的主机内存,不需要复制到GPU。在分配内存时加上cudaHostAllocMapped标志即可,该标志告诉陨石时将从GPU访问这块内存。
WriteCombined标志表示,运行时应该将内存分配为“合并式写入”内存。可以显著提升GPU读取内存的性能。然后,当CPU也要读取这块内存时,合并式写入会显得很低效。
调用cudaHostAlloc()将返回这块内存在CPU上的指针,需调用cudaHostGetDevicePointer()来获得这块内存在GPU上的有效指针。
通过cudaSetDeviceFlags()可实现在运行时置入能分配零拷贝内存的状态,通过传递标志cudaDeviceMapHost来表示我们希望设备映射主机内存。
当输入内存和输出内存都只能使用一次时,那么在独立GPU上使用零拷贝内存将带来性能提升。但由于GPU不会缓存零拷贝内存的内容,如果多次读取内存,那么最终将得不偿失,还不如一开始就将数据复制到GPU。
如果某个线程分配了固定内存,那么这些内存只是对于分配它们的线程来说是页锁定的,对于其他线程似乎是可分页的。对于这个问题的补救方案是:将固定内存分配为可移动的。这意味着在主机线程之间移动这块内存,并且每个线程都将其视为固定内存。要达到这个目标需要使用cudaHostAlloc()来分配内存,并且在调用时使用标志cudaHostAllocPortable。
编写多GPU代码中还有一点需要注意:一旦某个线程上设置了这个设备,那么将不能再次调用cudaSetDevice(),即便传递的是相同的设备标志符号。
#include "../common/book.h"
#define imin(a,b) (a<b?a:b)
#define N (33*1024*1024)
const int threadsPerBlock = 256;
const int blocksPerGrid =
imin( 32, (N/2+threadsPerBlock-1) / threadsPerBlock );
__global__ void dot( int size, float *a, float *b, float *c ) {
__shared__ float cache[threadsPerBlock];
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int cacheIndex = threadIdx.x;
float temp = 0;
while (tid < size) {
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
}
// set the cache values
cache[cacheIndex] = temp;
// synchronize threads in this block
__syncthreads();
// for reductions, threadsPerBlock must be a power of 2
// because of the following code
int i = blockDim.x/2;
while (i != 0) {
if (cacheIndex < i)
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads();
i /= 2;
}
if (cacheIndex == 0)
c[blockIdx.x] = cache[0];
}
struct DataStruct {
int deviceID;
int size;
int offset;
float *a;
float *b;
float returnValue;
};
void* routine( void *pvoidData ) {
DataStruct *data = (DataStruct*)pvoidData;
if (data->deviceID != 0) {
HANDLE_ERROR( cudaSetDevice( data->deviceID ) );
HANDLE_ERROR( cudaSetDeviceFlags( cudaDeviceMapHost ) );
}
int size = data->size;
float *a, *b, c, *partial_c;
float *dev_a, *dev_b, *dev_partial_c;
// allocate memory on the CPU side
a = data->a;
b = data->b;
partial_c = (float*)malloc( blocksPerGrid*sizeof(float) );
// allocate the memory on the GPU
HANDLE_ERROR( cudaHostGetDevicePointer( &dev_a, a, 0 ) );
HANDLE_ERROR( cudaHostGetDevicePointer( &dev_b, b, 0 ) );
HANDLE_ERROR( cudaMalloc( (void**)&dev_partial_c,
blocksPerGrid*sizeof(float) ) );
// offset 'a' and 'b' to where this GPU is gets it data
dev_a += data->offset;
dev_b += data->offset;
dot<<<blocksPerGrid,threadsPerBlock>>>( size, dev_a, dev_b,
dev_partial_c );
// copy the array 'c' back from the GPU to the CPU
HANDLE_ERROR( cudaMemcpy( partial_c, dev_partial_c,
blocksPerGrid*sizeof(float),
cudaMemcpyDeviceToHost ) );
// finish up on the CPU side
c = 0;
for (int i=0; i<blocksPerGrid; i++) {
c += partial_c[i];
}
HANDLE_ERROR( cudaFree( dev_partial_c ) );
// free memory on the CPU side
free( partial_c );
data->returnValue = c;
return 0;
}
int main( void ) {
int deviceCount;
HANDLE_ERROR( cudaGetDeviceCount( &deviceCount ) );
if (deviceCount < 2) {
printf( "We need at least two compute 1.0 or greater "
"devices, but only found %d\n", deviceCount );
return 0;
}
cudaDeviceProp prop;
for (int i=0; i<2; i++) {
HANDLE_ERROR( cudaGetDeviceProperties( &prop, i ) );
if (prop.canMapHostMemory != 1) {
printf( "Device %d can not map memory.\n", i );
return 0;
}
}
float *a, *b;
HANDLE_ERROR( cudaSetDevice( 0 ) );
HANDLE_ERROR( cudaSetDeviceFlags( cudaDeviceMapHost ) );
HANDLE_ERROR( cudaHostAlloc( (void**)&a, N*sizeof(float),
cudaHostAllocWriteCombined |
cudaHostAllocPortable |
cudaHostAllocMapped ) );
HANDLE_ERROR( cudaHostAlloc( (void**)&b, N*sizeof(float),
cudaHostAllocWriteCombined |
cudaHostAllocPortable |
cudaHostAllocMapped ) );
// fill in the host memory with data
for (int i=0; i<N; i++) {
a[i] = i;
b[i] = i*2;
}
// prepare for multithread
DataStruct data[2];
data[0].deviceID = 0;
data[0].offset = 0;
data[0].size = N/2;
data[0].a = a;
data[0].b = b;
data[1].deviceID = 1;
data[1].offset = N/2;
data[1].size = N/2;
data[1].a = a;
data[1].b = b;
CUTThread thread = start_thread( routine, &(data[1]) );
routine( &(data[0]) );
end_thread( thread );
// free memory on the CPU side
HANDLE_ERROR( cudaFreeHost( a ) );
HANDLE_ERROR( cudaFreeHost( b ) );
printf( "Value calculated: %f\n",
data[0].returnValue + data[1].returnValue );
return 0;
}
第10篇 附录
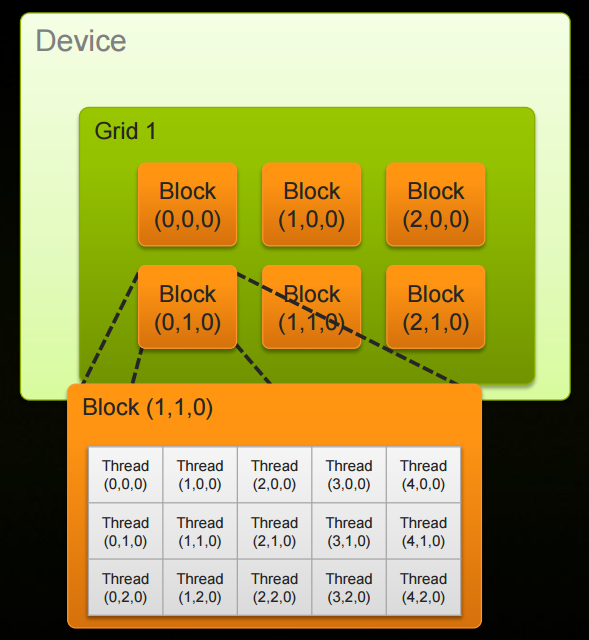
本篇主要附上了几个有助于理解CUDA C编程中一些概念的截图及上文代码的几个附属头文件。
几幅截图

几个头文件
book.h cpu_bitmap.h cpu.anim.h
#ifndef __BOOK_H__
#define __BOOK_H__
#include <stdio.h>
static void HandleError( cudaError_t err,
const char *file,
int line ) {
if (err != cudaSuccess) {
printf( "%s in %s at line %d\n", cudaGetErrorString( err ),
file, line );
exit( EXIT_FAILURE );
}
}
#define HANDLE_ERROR( err ) (HandleError( err, __FILE__, __LINE__ ))
#define HANDLE_NULL( a ) {if (a == NULL) { \
printf( "Host memory failed in %s at line %d\n", \
__FILE__, __LINE__ ); \
exit( EXIT_FAILURE );}}
template< typename T >
void swap( T& a, T& b ) {
T t = a;
a = b;
b = t;
}
void* big_random_block( int size ) {
unsigned char *data = (unsigned char*)malloc( size );
HANDLE_NULL( data );
for (int i=0; i<size; i++)
data[i] = rand();
return data;
}
int* big_random_block_int( int size ) {
int *data = (int*)malloc( size * sizeof(int) );
HANDLE_NULL( data );
for (int i=0; i<size; i++)
data[i] = rand();
return data;
}
// a place for common kernels - starts here
__device__ unsigned char value( float n1, float n2, int hue ) {
if (hue > 360) hue -= 360;
else if (hue < 0) hue += 360;
if (hue < 60)
return (unsigned char)(255 * (n1 + (n2-n1)*hue/60));
if (hue < 180)
return (unsigned char)(255 * n2);
if (hue < 240)
return (unsigned char)(255 * (n1 + (n2-n1)*(240-hue)/60));
return (unsigned char)(255 * n1);
}
__global__ void float_to_color( unsigned char *optr,
const float *outSrc ) {
// map from threadIdx/BlockIdx to pixel position
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float l = outSrc[offset];
float s = 1;
int h = (180 + (int)(360.0f * outSrc[offset])) % 360;
float m1, m2;
if (l <= 0.5f)
m2 = l * (1 + s);
else
m2 = l + s - l * s;
m1 = 2 * l - m2;
optr[offset*4 + 0] = value( m1, m2, h+120 );
optr[offset*4 + 1] = value( m1, m2, h );
optr[offset*4 + 2] = value( m1, m2, h -120 );
optr[offset*4 + 3] = 255;
}
__global__ void float_to_color( uchar4 *optr,
const float *outSrc ) {
// map from threadIdx/BlockIdx to pixel position
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float l = outSrc[offset];
float s = 1;
int h = (180 + (int)(360.0f * outSrc[offset])) % 360;
float m1, m2;
if (l <= 0.5f)
m2 = l * (1 + s);
else
m2 = l + s - l * s;
m1 = 2 * l - m2;
optr[offset].x = value( m1, m2, h+120 );
optr[offset].y = value( m1, m2, h );
optr[offset].z = value( m1, m2, h -120 );
optr[offset].w = 255;
}
#if _WIN32
//Windows threads.
#include <windows.h>
typedef HANDLE CUTThread;
typedef unsigned (WINAPI *CUT_THREADROUTINE)(void *);
#define CUT_THREADPROC unsigned WINAPI
#define CUT_THREADEND return 0
#else
//POSIX threads.
#include <pthread.h>
typedef pthread_t CUTThread;
typedef void *(*CUT_THREADROUTINE)(void *);
#define CUT_THREADPROC void
#define CUT_THREADEND
#endif
//Create thread.
CUTThread start_thread( CUT_THREADROUTINE, void *data );
//Wait for thread to finish.
void end_thread( CUTThread thread );
//Destroy thread.
void destroy_thread( CUTThread thread );
//Wait for multiple threads.
void wait_for_threads( const CUTThread *threads, int num );
#if _WIN32
//Create thread
CUTThread start_thread(CUT_THREADROUTINE func, void *data){
return CreateThread(NULL, 0, (LPTHREAD_START_ROUTINE)func, data, 0, NULL);
}
//Wait for thread to finish
void end_thread(CUTThread thread){
WaitForSingleObject(thread, INFINITE);
CloseHandle(thread);
}
//Destroy thread
void destroy_thread( CUTThread thread ){
TerminateThread(thread, 0);
CloseHandle(thread);
}
//Wait for multiple threads
void wait_for_threads(const CUTThread * threads, int num){
WaitForMultipleObjects(num, threads, true, INFINITE);
for(int i = 0; i < num; i++)
CloseHandle(threads[i]);
}
#else
//Create thread
CUTThread start_thread(CUT_THREADROUTINE func, void * data){
pthread_t thread;
pthread_create(&thread, NULL, func, data);
return thread;
}
//Wait for thread to finish
void end_thread(CUTThread thread){
pthread_join(thread, NULL);
}
//Destroy thread
void destroy_thread( CUTThread thread ){
pthread_cancel(thread);
}
//Wait for multiple threads
void wait_for_threads(const CUTThread * threads, int num){
for(int i = 0; i < num; i++)
end_thread( threads[i] );
}
#endif
#endif // __BOOK_H__
#ifndef __CPU_BITMAP_H__
#define __CPU_BITMAP_H__
#include "gl_helper.h"
struct CPUBitmap {
unsigned char *pixels;
int x, y;
void *dataBlock;
void (*bitmapExit)(void*);
CPUBitmap( int width, int height, void *d = NULL ) {
pixels = new unsigned char[width * height * 4];
x = width;
y = height;
dataBlock = d;
}
~CPUBitmap() {
delete [] pixels;
}
unsigned char* get_ptr( void ) const { return pixels; }
long image_size( void ) const { return x * y * 4; }
void display_and_exit( void(*e)(void*) = NULL ) {
CPUBitmap** bitmap = get_bitmap_ptr();
*bitmap = this;
bitmapExit = e;
// a bug in the Windows GLUT implementation prevents us from
// passing zero arguments to glutInit()
int c=1;
char* dummy = "";
glutInit( &c, &dummy );
glutInitDisplayMode( GLUT_SINGLE | GLUT_RGBA );
glutInitWindowSize( x, y );
glutCreateWindow( "bitmap" );
glutKeyboardFunc(Key);
glutDisplayFunc(Draw);
glutMainLoop();
}
// static method used for glut callbacks
static CPUBitmap** get_bitmap_ptr( void ) {
static CPUBitmap *gBitmap;
return &gBitmap;
}
// static method used for glut callbacks
static void Key(unsigned char key, int x, int y) {
switch (key) {
case 27:
CPUBitmap* bitmap = *(get_bitmap_ptr());
if (bitmap->dataBlock != NULL && bitmap->bitmapExit != NULL)
bitmap->bitmapExit( bitmap->dataBlock );
exit(0);
}
}
// static method used for glut callbacks
static void Draw( void ) {
CPUBitmap* bitmap = *(get_bitmap_ptr());
glClearColor( 0.0, 0.0, 0.0, 1.0 );
glClear( GL_COLOR_BUFFER_BIT );
glDrawPixels( bitmap->x, bitmap->y, GL_RGBA, GL_UNSIGNED_BYTE, bitmap->pixels );
glFlush();
}
};
#endif // __CPU_BITMAP_H__
#ifndef __CPU_ANIM_H__
#define __CPU_ANIM_H__
#include "gl_helper.h"
#include <iostream>
struct CPUAnimBitmap {
unsigned char *pixels;
int width, height;
void *dataBlock;
void (*fAnim)(void*,int);
void (*animExit)(void*);
void (*clickDrag)(void*,int,int,int,int);
int dragStartX, dragStartY;
CPUAnimBitmap( int w, int h, void *d = NULL ) {
width = w;
height = h;
pixels = new unsigned char[width * height * 4];
dataBlock = d;
clickDrag = NULL;
}
~CPUAnimBitmap() {
delete [] pixels;
}
unsigned char* get_ptr( void ) const { return pixels; }
long image_size( void ) const { return width * height * 4; }
void click_drag( void (*f)(void*,int,int,int,int)) {
clickDrag = f;
}
void anim_and_exit( void (*f)(void*,int), void(*e)(void*) ) {
CPUAnimBitmap** bitmap = get_bitmap_ptr();
*bitmap = this;
fAnim = f;
animExit = e;
// a bug in the Windows GLUT implementation prevents us from
// passing zero arguments to glutInit()
int c=1;
char* dummy = "";
glutInit( &c, &dummy );
glutInitDisplayMode( GLUT_DOUBLE | GLUT_RGBA );
glutInitWindowSize( width, height );
glutCreateWindow( "bitmap" );
glutKeyboardFunc(Key);
glutDisplayFunc(Draw);
if (clickDrag != NULL)
glutMouseFunc( mouse_func );
glutIdleFunc( idle_func );
glutMainLoop();
}
// static method used for glut callbacks
static CPUAnimBitmap** get_bitmap_ptr( void ) {
static CPUAnimBitmap* gBitmap;
return &gBitmap;
}
// static method used for glut callbacks
static void mouse_func( int button, int state,
int mx, int my ) {
if (button == GLUT_LEFT_BUTTON) {
CPUAnimBitmap* bitmap = *(get_bitmap_ptr());
if (state == GLUT_DOWN) {
bitmap->dragStartX = mx;
bitmap->dragStartY = my;
} else if (state == GLUT_UP) {
bitmap->clickDrag( bitmap->dataBlock,
bitmap->dragStartX,
bitmap->dragStartY,
mx, my );
}
}
}
// static method used for glut callbacks
static void idle_func( void ) {
static int ticks = 1;
CPUAnimBitmap* bitmap = *(get_bitmap_ptr());
bitmap->fAnim( bitmap->dataBlock, ticks++ );
glutPostRedisplay();
}
// static method used for glut callbacks
static void Key(unsigned char key, int x, int y) {
switch (key) {
case 27:
CPUAnimBitmap* bitmap = *(get_bitmap_ptr());
bitmap->animExit( bitmap->dataBlock );
//delete bitmap;
exit(0);
}
}
// static method used for glut callbacks
static void Draw( void ) {
CPUAnimBitmap* bitmap = *(get_bitmap_ptr());
glClearColor( 0.0, 0.0, 0.0, 1.0 );
glClear( GL_COLOR_BUFFER_BIT );
glDrawPixels( bitmap->width, bitmap->height, GL_RGBA, GL_UNSIGNED_BYTE, bitmap->pixels );
glutSwapBuffers();
}
};
#endif // __CPU_ANIM_H__
参考
[1] GPU高性能编程CUDA实战
[2] CUDA By Example,书及源码
[3] CUDA C/C++ Basics,Cyril Zeller, NVIDIA Corporation



