
写在前面
C++11加入了多线程编程的支持,目前讲C++并发编程最好的书籍是《C++ Concurrency In Action》,因为中文版的翻译被黑出了翔,直接读的英文原版。因为书中讲的比较深,加上英语理解的难度,读了两遍才懵懵懂懂的读懂了一些。多线程编程相对于多进程编程而言,共享地址空间,与此同时伴随着共享数据的竞争等问题。为了实现线程安全性,主要有两种方法,一种是使用互斥量或条件变量实现保护,另一种是高级无锁编程。下文是一些笔记,方便用到的时候查阅复习。
第1章 你好,C++的并发世界
使用并发编程的主要原因有两个:关注点分离(SOC)和性能。
#include <iostream>
#include <thread>
void hello()
{
std::cout<<"Hello Concurrent World\n";
}
int main()
{
std::thread t(hello);
t.join();
}
第2章 线程管理
本章主要介绍了启动新线程、等待线程与分离线程、线程唯一标识符。
线程在std::thread对象创建(为线程指定任务)时启动。
同大多数C++标准库一样,std::thread可以用可调用(callable)类型构造,将带有函数调用符类型的实例传入std::thread类中,替换默认的构造函数。
有件事需要注意,当把函数对象传入到线程构造函数中时,需要避免“最令人头痛的语法解析”(C++’s most vexing parse, 中文简介)。如果你传递了一个临时变量,而不是一个命名的变量;C++编译器会将其解析为函数声明,而不是类型对象的定义。例如:
std::thread my_thread(background_task());
这里相当与声明了一个名为my_thread的函数,这个函数带有一个参数(函数指针指向没有参数并返回background_task对象的函数),返回一个std::thread对象的函数,而非启动了一个线程。
使用在前面命名函数对象的方式,或使用多组括号①,或使用新统一的初始化语法②,可以避免这个问题。如下所示:
std::thread my_thread((background_task()));
std::thread my_thread{background_task()};
使用lambda表达式也能避免这个问题。
std::thread my_thread([]{do_something();do_something_else();});
只能对一个线程使用一次join();一旦已经使用过join(),std::thread对象就不能再次加入了,当对其使用joinable()时,将返回否(false)。
std::thread::hardware_concurrency()在新版C++标准库中是一个很有用的函数。这个函数将返回能同时并发在一个程序中的线程数量。
#include <thread>
#include <numeric>
#include <algorithm>
#include <functional>
#include <vector>
#include <iostream>
template<typename Iterator,typename T>
struct accumulate_block
{
void operator()(Iterator first,Iterator last,T& result)
{
result=std::accumulate(first,last,result);
}
};
template<typename Iterator,typename T>
T parallel_accumulate(Iterator first,Iterator last,T init)
{
unsigned long const length=std::distance(first,last);
if(!length)
return init;
unsigned long const min_per_thread=25;
unsigned long const max_threads=(length+min_per_thread-1)/min_per_thread;
unsigned long const hardware_threads=std::thread::hardware_concurrency();
unsigned long const num_threads=std::min(hardware_threads!=0?hardware_threads:2,max_threads);
unsigned long const block_size=length/num_threads;
std::vector<T> results(num_threads);
std::vector<std::thread> threads(num_threads-1);
Iterator block_start=first;
for(unsigned long i=0;i<(num_threads-1);++i)
{
Iterator block_end=block_start;
std::advance(block_end,block_size);
threads[i]=std::thread(accumulate_block<Iterator,T>(),block_start,block_end,std::ref(results[i]));
block_start=block_end;
}
accumulate_block<Iterator,T>()(block_start,last,results[num_threads-1]);
std::for_each(threads.begin(),threads.end(), std::mem_fn(&std::thread::join));
return std::accumulate(results.begin(),results.end(),init);
}
int main()
{
std::vector<int> vi;
for(int i=0;i<10;++i)
{
vi.push_back(10);
}
int sum=parallel_accumulate(vi.begin(),vi.end(),5);
std::cout<<"sum="<<sum<<std::endl;
}
线程标识类型是std::thread::id,可以通过两种方式进行检索。第一种,可以通过调用std::thread对象的成员函数get_id()来直接获取。如果std::thread对象没有与任何执行线程相关联,get_id()将返回std::thread::type默认构造值,这个值表示“没有线程”。第二种,当前线程中调用std::this_thread::get_id()(这个函数定义在
第3章 线程间共享数据
本章主要介绍了共享数据带来的问题、使用互斥量保护数据、数据保护的替代方案。
这里提供一些方法来解决恶性条件竞争,最简单的办法就是对数据结构采用某种保护机制,确保只有进行修改的线程才能看到不变量被破坏时的中间状态。从其他访问线程的角度来看,修改不是已经完成了,就是还没开始。
另一个选择是对数据结构和不变量的设计进行修改,修改完的结构必须能完成一系列不可分割的变化,也就是保证每个不变量保持稳定的状态,这就是所谓的无锁编程(lock-free programming)。
保护共享数据结构的最基本的方式,是使用C++标准库提供的互斥量(mutex)。
C++中通过实例化std::mutex创建互斥量,通过调用成员函数lock()进行上锁,unlock()进行解锁。不过,不推荐实践中直接去调用成员函数,因为调用成员函数就意味着,必须记住在每个函数出口都要去调用unlock(),也包括异常的情况。C++标准库为互斥量提供了一个RAII语法的模板类std::lock_guard,其会在构造的时候提供已锁的互斥量,并在析构的时候进行解锁,从而保证了一个已锁的互斥量总是会被正确的解锁
#include <list>
#include <mutex>
#include <algorithm>
std::list<int> some_list;
std::mutex some_mutex;
void add_to_list(int new_value)
{
std::lock_guard<std::mutex> guard(some_mutex);
some_list.push_back(new_value);
}
bool list_contains(int value_to_find)
{
std::lock_guard<std::mutex> guard(some_mutex);
return std::find(some_list.begin(),some_list.end(),value_to_find)
!= some_list.end();
}
#include <iostream>
int main()
{
add_to_list(42);
std::cout<<"contains(1)="<<list_contains(1)<<", contains(42)="<<list_contains(42)<<std::endl;
}
互斥量和要保护的数据,在类中都需要定义为private成员,这会让访问数据的代码变的清晰,并且容易看出在什么时候对互斥量上锁。
切勿将受保护数据的指针或引用传递到互斥锁作用域之外,无论是函数返回值,还是存储在外部可见内存,亦或是以参数的形式传递到用户提供的函数中去。
#include <exception>
#include <stack>
#include <mutex>
#include <memory>
struct empty_stack: std::exception
{
const char* what() const throw()
{
return "empty stack";
}
};
template<typename T>
class threadsafe_stack
{
private:
std::stack<T> data;
mutable std::mutex m;
public:
threadsafe_stack(){}
threadsafe_stack(const threadsafe_stack& other)
{
std::lock_guard<std::mutex> lock(other.m);
data=other.data;
}
threadsafe_stack& operator=(const threadsafe_stack&) = delete;
void push(T new_value)
{
std::lock_guard<std::mutex> lock(m);
data.push(new_value);
}
std::shared_ptr<T> pop()
{
std::lock_guard<std::mutex> lock(m);
if(data.empty()) throw empty_stack();
std::shared_ptr<T> const res(std::make_shared<T>(data.top()));
data.pop();
return res;
}
void pop(T& value)
{
std::lock_guard<std::mutex> lock(m);
if(data.empty()) throw empty_stack();
value=data.top();
data.pop();
}
bool empty() const
{
std::lock_guard<std::mutex> lock(m);
return data.empty();
}
};
int main()
{
threadsafe_stack<int> si;
si.push(5);
si.pop();
if(!si.empty())
{
int x;
si.pop(x);
}
}
死锁:鼓和鼓锤。
避免死锁的一般建议,就是让两个互斥量总以相同的顺序上锁:总在互斥量B之前锁住互斥量A,就永远不会死锁。
交换操作中使用std::lock()和std::lock_guard
#include <mutex>
class some_big_object
{};
void swap(some_big_object& lhs,some_big_object& rhs)
{}
class X
{
private:
some_big_object some_detail;
mutable std::mutex m;
public:
X(some_big_object const& sd):some_detail(sd){}
friend void swap(X& lhs, X& rhs)
{
if(&lhs==&rhs)
return;
std::lock(lhs.m,rhs.m);
std::lock_guard<std::mutex> lock_a(lhs.m,std::adopt_lock);
std::lock_guard<std::mutex> lock_b(rhs.m,std::adopt_lock);
swap(lhs.some_detail,rhs.some_detail);
}
};
int main()
{}
调用std::lock()①锁住两个互斥量,并且两个std:lock_guard实例已经创建好②③,还有一个互斥量。提供std::adopt_lock参数除了表示std::lock_guard对象已经上锁外,还表示现成的锁,而非尝试创建新的锁。std::lock要么将两个锁都锁住,要不一个都不锁。
避免死锁的进阶指导:
1 避免嵌套锁。第一个建议往往是最简单的:一个线程已获得一个锁时,再别去获取第二个。
2 避免在持有锁时调用用户提供的代码。
3 使用固定顺序获取锁。当硬性条件要求你获取两个以上(包括两个)的锁,并且不能使用std::lock单独操作来获取它们;那么最好在每个线程上,用固定的顺序获取它们获取它们(锁)。
4 使用锁的层次结构。
虽然hierarchical_mutex不是C++标准的一部分,但是它写起来很容易;一个简单的实现在列表3.8中展示出来。尽管它是一个用户定义类型,它可以用于std::lock_guard<>模板中,因为它的实现有三个成员函数为了满足互斥量操作:lock(), unlock() 和 try_lock()。
#include <mutex>
#include <stdexcept>
#include <climits>
class hierarchical_mutex
{
std::mutex internal_mutex;
unsigned long const hierarchy_value;
unsigned long previous_hierarchy_value;
static thread_local unsigned long this_thread_hierarchy_value;
void check_for_hierarchy_violation()
{
if(this_thread_hierarchy_value <= hierarchy_value)
{
throw std::logic_error("mutex hierarchy violated");
}
}
void update_hierarchy_value()
{
previous_hierarchy_value=this_thread_hierarchy_value;
this_thread_hierarchy_value=hierarchy_value;
}
public:
explicit hierarchical_mutex(unsigned long value):
hierarchy_value(value),
previous_hierarchy_value(0)
{}
void lock()
{
check_for_hierarchy_violation();
internal_mutex.lock();
update_hierarchy_value();
}
void unlock()
{
this_thread_hierarchy_value=previous_hierarchy_value;
internal_mutex.unlock();
}
bool try_lock()
{
check_for_hierarchy_violation();
if(!internal_mutex.try_lock())
return false;
update_hierarchy_value();
return true;
}
};
thread_local unsigned long hierarchical_mutex::this_thread_hierarchy_value(ULONG_MAX);
int main()
{
hierarchical_mutex m1(42);
hierarchical_mutex m2(2000);
//std::lock_guard<hirearchical_mutex> lk(m1); //使用示范
}
因为其声明中有thread_local,所以每个线程都有其拷贝副本,这样线程中变量状态完全独立,当从另一个线程进行读取时,变量的状态也完全独立。
5 超越锁的延伸扩展。
当代码已经能规避死锁,std::lock()和std::lock_guard能组成简单的锁覆盖大多数情况,但是有时需要更多的灵活性。在这些情况,可以使用标准库提供的std::unique_lock模板。如std::lock_guard,这是一个参数化的互斥量模板类,并且它提供很多RAII类型锁用来管理std::lock_guard类型,可以让代码更加灵活。
std::unqiue_lock使用更为自由的不变量,这样std::unique_lock实例不会总与互斥量的数据类型相关,使用起来要比std:lock_guard更加灵活。首先,可将std::adopt_lock作为第二个参数传入构造函数,对互斥量进行管理;也可以将std::defer_lock作为第二个参数传递进去,表明互斥量应保持解锁状态。这样,就可以被std::unique_lock对象(不是互斥量)的lock()函数的所获取,或传递std::unique_lock对象到std::lock()中。
std::unique_lock实例没有与自身相关的互斥量,一个互斥量的所有权可以通过移动操作,在不同的实例中进行传递。某些情况下,这种转移是自动发生的,例如:当函数返回一个实例;另些情况下,需要显式的调用std::move()来执行移动操作。
互斥量是最通用的机制,但其并非保护共享数据的唯一方式。这里有很多替代方式可以在特定情况下,提供更加合适的保护。
保护共享数据的初始化过程。
比起锁住互斥量,并显式的检查指针,每个线程只需要使用std::call_once,在std::call_once的结束时,就能安全的知道指针已经被其他的线程初始化了。使用std::call_once比显式使用互斥量消耗的资源更少,特别是当初始化完成后。
使用std::call_once作为类成员的延迟初始化 线程安全
#include <mutex>
struct connection_info
{};
struct data_packet
{};
struct connection_handle
{
void send_data(data_packet const&)
{}
data_packet receive_data()
{
return data_packet();
}
};
struct remote_connection_manager
{
connection_handle open(connection_info const&)
{
return connection_handle();
}
} connection_manager;
class X
{
private:
connection_info connection_details;
connection_handle connection;
std::once_flag connection_init_flag;
void open_connection()
{
connection=connection_manager.open(connection_details);
}
public:
X(connection_info const& connection_details_):
connection_details(connection_details_)
{}
void send_data(data_packet const& data)
{
std::call_once(connection_init_flag,&X::open_connection,this);
connection.send_data(data);
}
data_packet receive_data()
{
std::call_once(connection_init_flag,&X::open_connection,this);
return connection.receive_data();
}
};
保护更少更新的数据。
“读者-写者锁”(reader-writer mutex)。
比起使用std::mutex实例进行同步,不如使用boost::shared_mutex来做同步。对于更新操作,可以使用std::lock_guardboost::shared_mutex和std::unique_lockboost::shared_mutex上锁。
使用boost::shared_mutex对数据结构进行保护
#include <map>
#include <string>
#include <mutex>
#include <boost/thread/shared_mutex.hpp>
class dns_entry
{};
class dns_cache
{
std::map<std::string,dns_entry> entries;
boost::shared_mutex entry_mutex;
public:
dns_entry find_entry(std::string const& domain)
{
boost::shared_lock<boost::shared_mutex> lk(entry_mutex);
std::map<std::string,dns_entry>::const_iterator const it=entries.find(domain);
return (it==entries.end())?dns_entry():it->second;
}
void update_or_add_entry(std::string const& domain,
dns_entry const& dns_details)
{
std::lock_guard<boost::shared_mutex> lk(entry_mutex);
entries[domain]=dns_details;
}
};
本章讨论了当两个线程间的共享数据发生恶性条件竞争会带来多么严重的灾难,还讨论了如何使用std::mutex,和如何避免这些问题。如你所见,互斥量并不是灵丹妙药,其还有自己的问题(比如:死锁),虽然C++标准库提供了一类工具来避免这些(例如:std::lock())。你还见识了一些用于避免死锁的先进技术,之后了解了锁所有权的转移,以及一些围绕如何选取适当粒度锁产生的问题。最后,讨论了在具体情况下,数据保护的替代方案,例如:std::call_once()和boost::shared_mutex。
第4章中,会去建立一些工具,用于保护共享数据,还会介绍一些线程同步操作的机制
第4章 同步并发操作
本章主要介绍等待事件、带有期望的等待一次性事件、在限定时间内等待、使用同步操作简化代码。
当一个线程等待另一个线程完成任务时,他会有很多选择:
第一,它可以持续的检查共享数据标志(用于做保护工作的互斥量),直到另一线程完成工作时对这个标志进行重设。
第二个选择是在等待线程在检查间隙,使用std::this_thread::sleep_for()进行周期性的间歇(详见4.3节):
第三个选择(也是优先的选择)是,使用C++标准库提供的工具去等待事件的发生。通过另一线程触发等待事件的机制是最基本的唤醒方式(例如:流水线上存在额外的任务时),这种机制就称为“条件变量”(condition variable)。
C++标准库对条件变量有两套实现:std::condition_variable和std::condition_variable_any。这两个实现都包含在
使用std::condition_variable处理数据等待
#include <mutex>
#include <condition_variable>
#include <thread>
#include <queue>
bool more_data_to_prepare()
{
return false;
}
struct data_chunk
{};
data_chunk prepare_data()
{
return data_chunk();
}
void process(data_chunk&)
{}
bool is_last_chunk(data_chunk&)
{
return true;
}
std::mutex mut;
std::queue<data_chunk> data_queue;
std::condition_variable data_cond;
void data_preparation_thread()
{
while(more_data_to_prepare())
{
data_chunk const data=prepare_data();
std::lock_guard<std::mutex> lk(mut);
data_queue.push(data);
data_cond.notify_one();
}
}
void data_processing_thread()
{
while(true)
{
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk,[]{return !data_queue.empty();});
data_chunk data=data_queue.front();
data_queue.pop();
lk.unlock();
process(data);
if(is_last_chunk(data))
break;
}
}
int main()
{
std::thread t1(data_preparation_thread);
std::thread t2(data_processing_thread);
t1.join();
t2.join();
}
为什么用std::unique_lock而不使用std::lock_guard?等待中的线程必须在等待期间解锁互斥量,并在这这之后对互斥量再次上锁,而std::lock_guard没有这么灵活。
#include <mutex>
#include <condition_variable>
#include <queue>
#include <memory>
template<typename T>
class threadsafe_queue
{
private:
mutable std::mutex mut;
std::queue<T> data_queue;
std::condition_variable data_cond;
public:
threadsafe_queue()
{}
threadsafe_queue(threadsafe_queue const& other)
{
std::lock_guard<std::mutex> lk(other.mut);
data_queue=other.data_queue;
}
void push(T new_value)
{
std::lock_guard<std::mutex> lk(mut);
data_queue.push(new_value);
data_cond.notify_one();
}
void wait_and_pop(T& value)
{
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk,[this]{return !data_queue.empty();});
value=data_queue.front();
data_queue.pop();
}
std::shared_ptr<T> wait_and_pop()
{
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk,[this]{return !data_queue.empty();});
std::shared_ptr<T> res(std::make_shared<T>(data_queue.front()));
data_queue.pop();
return res;
}
bool try_pop(T& value)
{
std::lock_guard<std::mutex> lk(mut);
if(data_queue.empty)
return false;
value=data_queue.front();
data_queue.pop();
}
std::shared_ptr<T> try_pop()
{
std::lock_guard<std::mutex> lk(mut);
if(data_queue.empty())
return std::shared_ptr<T>();
std::shared_ptr<T> res(std::make_shared<T>(data_queue.front()));
data_queue.pop();
return res;
}
bool empty() const
{
std::lock_guard<std::mutex> lk(mut);
return data_queue.empty();
}
};
当等待线程只等待一次,当条件为true时,它就不会再等待条件变量了,所以一个条件变量可能并非同步机制的最好选择。尤其是,条件在等待一组可用的数据块时。在这样的情况下,期望(future)就是一个适合的选择。
在C++标准库中,有两种“期望”,使用两种类型模板实现,声明在头文件中: 唯一期望(unique futures)(std::future<>)和共享期望(shared futures)(std::shared_future<>)。
std::future的实例只能与一个指定事件相关联,而std::shared_future的实例就能关联多个事件。后者的实现中,所有实例会在同时变为就绪状态,并且他们可以访问与事件相关的任何数据。
在与数据无关的地方,可以使用std::future
当任务的结果你不着急要时,你可以使用std::async启动一个异步任务。与std::thread对象等待运行方式的不同,std::async会返回一个std::future对象,这个对象持有最终计算出来的结果。当你需要这个值时,你只需要调用这个对象的get()成员函数;并且直到“期望”状态为就绪的情况下,线程才会阻塞;之后,返回计算结果。
#include <future>
#include <iostream>
int find_the_answer_to_ltuae()
{
return 42;
}
void do_other_stuff()
{}
int main()
{
std::future<int> the_answer=std::async(find_the_answer_to_ltuae);
do_other_stuff();
std::cout<<"The answer is "<<the_answer.get()<<std::endl;
}
与std::thread 做的方式一样,std::async允许你通过添加额外的调用参数,向函数传递额外的参数。当第一个参数是一个指向成员函数的指针,第二个参数提供有这个函数成员类的具体对象(不是直接的,就是通过指针,还可以包装在std::ref中),剩余的参数可作为成员函数的参数传入。否则,第二个和随后的参数将作为函数的参数,或作为指定可调用对象的第一个参数。就如std::thread,当参数为右值(rvalues)时,拷贝操作将使用移动的方式转移原始数据。这就允许使用“只移动”类型作为函数对象和参数。
使用std::async会让分割算法到各个任务中变的容易,这样程序就能并发的执行了。不过,这不是让一个std::future与一个任务实例相关联的唯一方式;你也可以将任务包装入一个std::packaged_task<>实例中,或通过编写代码的方式,使用std::promise<>类型模板显示设置值。与std::promise<>对比,std::packaged_task<>具有更高层的抽象,所以我们从“高抽象”的模板说起。
std::packaged_task<>对一个函数或可调用对象,绑定一个期望。当std::packaged_task<> 对象被调用,它就会调用相关函数或可调用对象,将期望状态置为就绪,返回值也会被存储为相关数据。
使用std::packaged_task执行一个图形界面线程
#include <deque>
#include <mutex>
#include <future>
#include <thread>
#include <utility>
std::mutex m;
std::deque<std::packaged_task<void()> > tasks;
bool gui_shutdown_message_received();
void get_and_process_gui_message();
void gui_thread()
{
while(!gui_shutdown_message_received())
{
get_and_process_gui_message();
std::packaged_task<void()> task;
{
std::lock_guard<std::mutex> lk(m);
if(tasks.empty())
continue;
task=std::move(tasks.front());
tasks.pop_front();
}
task();
}
}
std::thread gui_bg_thread(gui_thread);
template<typename Func>
std::future<void> post_task_for_gui_thread(Func f)
{
std::packaged_task<void()> task(f);
std::future<void> res=task.get_future();
std::lock_guard<std::mutex> lk(m);
tasks.push_back(std::move(task));
return res;
}
#include <future>
void process_connections(connection_set& connections)
{
while(!done(connections))
{
for(connection_iterator connection=connections.begin(),end=connections.end(); connection!=end; ++connection)
{
if(connection->has_incoming_data())
{
data_packet data=connection->incoming();
std::promise<payload_type>& p=connection->get_promise(data.id);
p.set_value(data.payload);
}
if(connection->has_outgoing_data())
{
outgoing_packet data=connection->top_of_outgoing_queue();
connection->send(data.payload);
data.promise.set_value(true);
}
}
}
}
std::future也有局限性,在很多线程在等待的时候,只有一个线程能获取等待结果。当多个线程需要等待相同的事件的结果,你就需要使用std::shared_future来替代std::future了。
处理持续时间的变量以“_for”作为后缀,处理绝对时间的变量以"_until"作为后缀。
稳定闹钟对于超时的计算很重要,所以C++标准库提供一个稳定时钟std::chrono::steady_clock。C++标准库提供的其他时钟可表示为std::chrono::system_clock(在上面已经提到过),它代表了系统时钟的“实际时间”,并且提供了函数可将时间点转化为time_t类型的值;std::chrono::high_resolution_clock可能是标准库中提供的具有最小节拍周期(因此具有最高的精度[分辨率])的时钟。
时延是时间部分最简单的;std::chrono::duration<>函数模板能够对时延进行处理(线程库使用到的所有C++时间处理工具,都在std::chrono命名空间内)。第一个模板参数是一个类型表示(比如,int,long或double),第二个模板参数是制定部分,表示每一个单元所用秒数。例如,当几分钟的时间要存在short类型中时,可以写成std::chrono::duration
显示转换可以由std::chrono::duration_cast<>来完成。
std::future<int> f=std::async(some_task);
if(f.wait_for(std::chrono::milliseconds(35))==std::future_status::ready)
do_something_with(f.get());
auto start=std::chrono::high_resolution_clock::now();
do_something();
auto stop=std::chrono::high_resolution_clock::now();
std::cout<<"do_something() took" <<std::chrono::duration<double,std::chrono::seconds>(stop-start).count() <<” seconds”<<std::endl;
两个处理函数分别是std::this_thread::sleep_for()和std::this_thread::sleep_until()。他们的工作就像一个简单的闹钟:当线程因为指定时延而进入睡眠时,可使用sleep_for()唤醒;或因指定时间点睡眠的,可使用sleep_until唤醒。
std::mutex和std::recursive_mutex都不支持超时锁,但是std::timed_mutex和std::recursive_timed_mutex支持。
同步操作对于使用并发编写一款多线程应用来说,是很重要的一部分:如果没有同步,线程基本上就是独立的,也可写成单独的应用,因其任务之间的相关性,它们可作为一个群体直接执行。本章,我们讨论了各式各样的同步操作,从基本的条件变量,到“期望”、“承诺”,再到打包任务。我们也讨论了替代同步的解决方案:函数化模式编程,完全独立执行的函数,不会受到外部环境的影响;还有,消息传递模式,以消息子系统为中介,向线程异步的发送消息。
我们已经讨论了很多C++中的高层工具,现在我们来看一下底层工具是如何让一切都工作的:C++内存模型和原子操作。
第5章 C++内存模型和原子类型操作
本章主要介绍C++11内存模型、标准库提供的原子类型、使用各种原子类型、原子操作实现线程同步功能。
为了避免条件竞争,两个线程就需要一定的执行顺序。第一种方式,如第3章所述那样,使用互斥量来确定访问的顺序;当同一互斥量在两个线程同时访问前被锁住,那么在同一时间内就只有一个线程能够访问到对应的内存位置,所以后一个访问必须在前一个访问之后。另一种方式是使用原子操作(atmic operations)同步机制(详见5.2节中对于原子操作的定义),决定两个线程的访问顺序。
除了直接使用std::atomic<>类型模板外,你可以使用原子类型集。对于标准类型进行typedef T,相关的原子类型就在原来的类型名前加上atomic_的前缀:atomic_T。
通常,标准原子类型是不能拷贝和赋值,他们没有拷贝构造函数和拷贝赋值操作。但是,因为可以隐式转化成对应的内置类型,所以这些类型依旧支持赋值,可以使用load()和store()成员函数,exchange()、compare_exchange_weak()和compare_exchange_strong()。它们都支持复合赋值符:+=, -=, *=, |= 等等。并且使用整型和指针的特化类型还支持 ++ 和 --。当然,这些操作
也有功能相同的成员函数所对应:fetch_add(), fetch_or() 等等。
每种函数类型的操作都有一个可选内存排序参数,这个参数可以用来指定所需存储的顺序。在5.3节中,会对存储顺序选项进行详述。现在,只需要知道操作分为三类:
1 Store操作,可选如下顺序:memory_order_relaxed, memory_order_release, memory_order_seq_cst。
2 Load操作,可选如下顺序:memory_order_relaxed, memory_order_consume, memory_order_acquire, memory_order_seq_cst。
3 Read-modify-write(读-改-写)操作,可选如下顺序:memory_order_relaxed, memory_order_consume, memory_order_acquire, memory_order_release, memory_order_acq_rel,memory_order_seq_cst。所有操作的默认顺序都是memory_order_seq_cst。
std::atomic_flag类型的对象必须被ATOMIC_FLAG_INIT初始化。初始化标志位是“清除”状态。
当你的标志对象已初始化,那么你只能做三件事情:销毁,清除或设置(查询之前的值)。这些事情对应的函数分别是:clear()成员函数,和test_and_set()成员函数。
class spinlock_mutex
{
std::atomic_flag flag;
public:
spinlock_mutex():flag(ATOMIC_FLAG_INIT) {}
void lock()
{
while(flag.test_and_set(std::memory_order_acquire));
}
void unlock()
{
flag.clear(std::memory_order_release);
}
};
由于std::atomic_flag局限性太强,因为它没有非修改查询操作,它甚至不能像普通的布尔标志那样使用。
std::atomic的相关操作。
store()是一个存储操作,而load()是一个加载操作。exchange()是一个“读-改-写”操作:这是一种新型操作,叫做“比较/交换”,它的形式表现为compare_exchange_weak()和compare_exchange_strong()成员函数。
std::atomic
为了使用std::atomic
最后,这个类型必须是“位可比的”(bitwise equality comparable)。这与对赋值的要求差不多;你不仅需要确定,一个UDT类型对象可以使用memcpy()进行拷贝,还要确定其对象可以使用memcmp()对位进行比较。之所以要求这么多,是为了保证“比较/交换”操作能正常的工作。
当使用用户定义类型T进行实例化时,std::atomic
下图列举了每一个原子类型所能使用的操作。
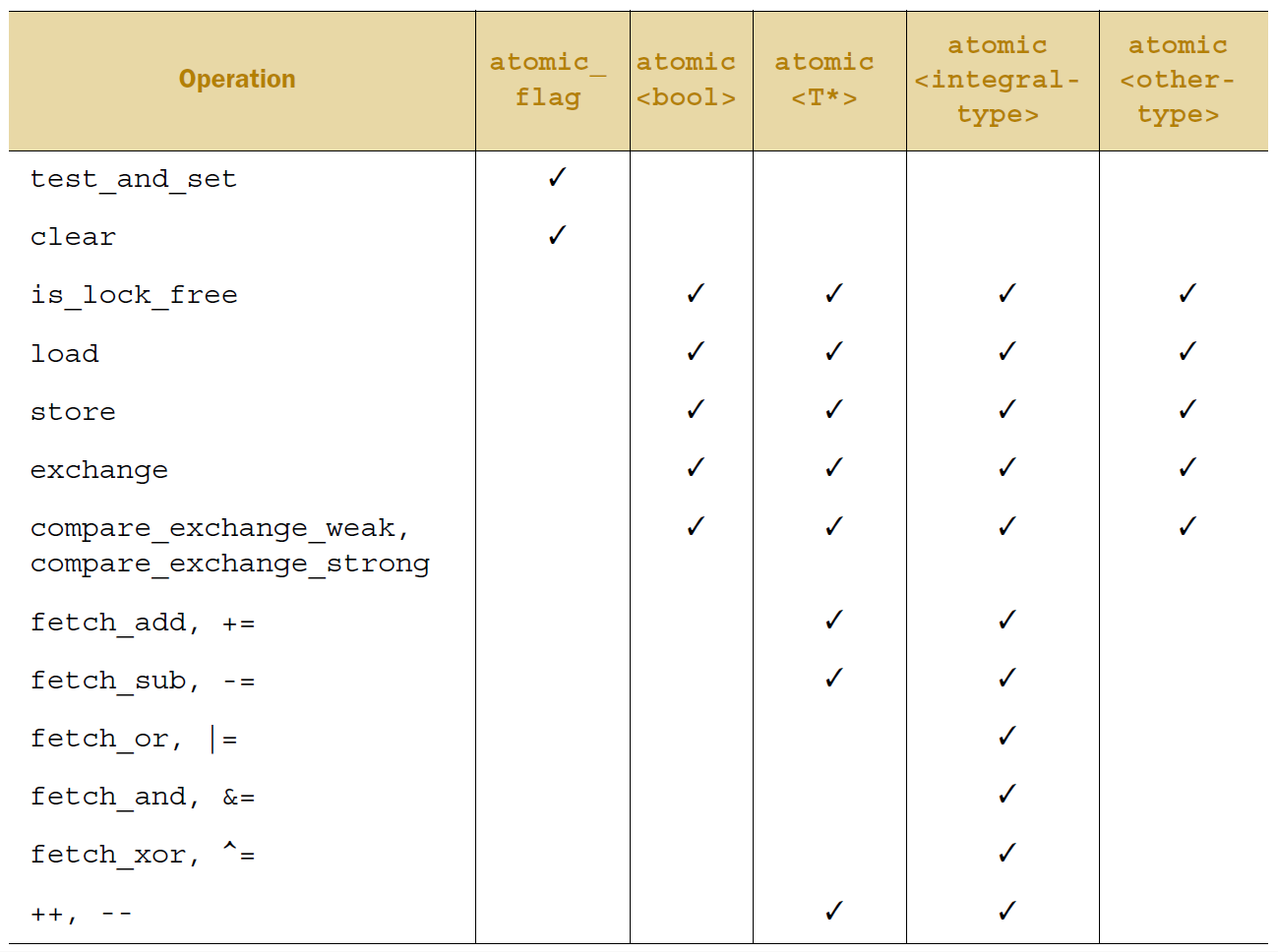
std::atomic_is_lock_free()只有一种类型(虽然会被其他类型所重载),并且对于同一个对象a,std::atomic_is_lock_free(&a)返回值与a.is_lock_free()相同。同样的,std::atomic_load(&a)和a.load()的作用一样,但需要注意的是,与a.load(std::memory_order_acquire)等价的操作是std::atomic_load_explicit(&a, std::memory_order_acquire)。
这里有六个内存序列选项可应用于对原子类型的操作:memory_order_relaxed, memory_order_consume, memory_order_acquire, memory_order_release, memory_order_acq_rel, 以及memory_order_seq_cst。除非你为特定的操作指定一个序列选项,要不内存序列选项对于所有原子类型默认都是memory_order_seq_cst。虽然有六个选项,但是它们仅代表三种内存模型:排序一致序列(sequentially consistent),获取-释放序列(memory_order_consume, memory_order_acquire, memory_order_release和memory_order_acq_rel),和自由序列(memory_order_relaxed)。
排序一致模型:序列一致是最简单、直观的序列,但是他也是最昂贵的内存序列,因为它需要对所有线程进行全局同步。在一个多处理系统上,这就需要处理期间进行大量并且费时的信息交换。
非排序一致内存模型:当你踏出序列一致的世界,所有事情就开始变的复杂。可能最需要处理的问题就是:再也不会有全局的序列了(there’s no longer a single global order of events)。这就意味着不同线程看到相同操作,不一定有着相同的顺序,还有对于不同线程的操作,都会整齐的,一个接着另一个执行的想法是需要摒弃的。
自由序列模型:为了了解自由序列是如何工作的,先将每一个变量想象成一个在独立房间中拿着记事本的人。他的记事本上是一组值的列表。你可以通过打电话的方式让他给你一个值,或让他写下一个新值。如果你告诉他写下一个新值,他会将这个新值写在表的最后。如果你让他给你一个值,他会从列表中读取一个值给你。
当存储操作被标记为memory_order_release,memory_order_acq_rel或memory_order_seq_cst,加载被标记为memory_order_consum,memory_order_acquire或memory_order_sqy_cst,并且操作链上的每一加载操作都会读取之前操作写入的值,因此链上的操作构成了一个释放序列(release sequence),并且初始化存储同步(对应memory_order_acquire或memory_order_seq_cst)或是前序依赖(对应memory_order_consume)的最终加载。操作链上的任何原子“读-改-写”操作可以拥有任意个存储序列(甚至是memory_order_relaxed)。
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x_then_y()
{
x.store(true,std::memory_order_relaxed);
std::atomic_thread_fence(std::memory_order_release);
y.store(true,std::memory_order_relaxed);
}
void read_y_then_x()
{
while(!y.load(std::memory_order_relaxed));
std::atomic_thread_fence(std::memory_order_acquire);
if(x.load(std::memory_order_relaxed))
++z;
}
int main()
{
x=false;
y=false;
z=0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load()!=0);
}
在本章中,已经对C++11内存模型的底层只是进行详尽的了解,并且了解了原子操作能在线程间提供基本的同步。这里包含基本的原子类型,由std::atomic<>类模板特化后提供;接口,以及对于这些类型的操作,还要有对内存序列选项的各种复杂细节,都由原始std::atomic<>类模板提供。
我们也了解了栅栏,了解其如何让执行序列中,对原子类型的操作同步成对。最后,我们回顾了本章开始的一些例子,了解了原子操作可以在不同线程上的非原子操作间,进行有序执行。
第6章 基于锁的并发数据结构设计
本章主要介绍并发数据结构设计的意义、指导如何设计、实现为并发设计的数据结构。
设计并发数据结构,意味着多个线程可以并发的访问这个数据结构,线程可对这个数据结构做相同或不同的操作,并且每一个线程都能在自己的自治域中看到该数据结构。且在多线程环境下,无数据丢失和损毁,所有的数据需要维持原样,且无条件竞争。这样的数据结构,称之为“线程安全”的数据结构。
当设计并发数据结构时,有两方面需要考量:一是确保访问是安全的,二是能真正的并发访问。
如何保证数据结构是线程安全:
1 确保无线程能够看到,数据结构的“不变量”破坏时的状态。
2 小心那些会引起条件竞争的接口,提供完整操作的函数,而非操作步骤。
3 注意数据结构的行为是否会产生异常,从而确保“不变量”的状态稳定。
4 将死锁的概率降到最低。使用数据结构时,需要限制锁的范围,且避免嵌套锁的存在。
确保真正的并发访问:
1 锁的范围中的操作,是否允许在所外执行?
2 数据结构中不同的区域是否能被不同的互斥量所保护?
3 所有操作都需要同级互斥量保护吗?
4 能否对数据结构进行简单的修改,以增加并发访问的概率,且不影响操作语义?
#include <queue>
#include <mutex>
#include <condition_variable>
#include <memory>
template<typename T>
class threadsafe_queue
{
private:
mutable std::mutex mut;
std::queue<T> data_queue;
std::condition_variable data_cond;
public:
threadsafe_queue()
{}
void push(T new_value)
{
std::lock_guard<std::mutex> lk(mut);
data_queue.push(std::move(new_value));
data_cond.notify_one();
}
void wait_and_pop(T& value)
{
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk,[this]{return !data_queue.empty();});
value=std::move(data_queue.front());
data_queue.pop();
}
std::shared_ptr<T> wait_and_pop()
{
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk,[this]{return !data_queue.empty();});
std::shared_ptr<T> res(
std::make_shared<T>(std::move(data_queue.front())));
data_queue.pop();
return res;
}
bool try_pop(T& value)
{
std::lock_guard<std::mutex> lk(mut);
if(data_queue.empty())
return false;
value=std::move(data_queue.front());
data_queue.pop();
}
std::shared_ptr<T> try_pop()
{
std::lock_guard<std::mutex> lk(mut);
if(data_queue.empty())
return std::shared_ptr<T>();
std::shared_ptr<T> res(
std::make_shared<T>(std::move(data_queue.front())));
data_queue.pop();
return res;
}
bool empty() const
{
std::lock_guard<std::mutex> lk(mut);
return data_queue.empty();
}
};
int main()
{
threadsafe_queue<int> rq;
}
#include <queue>
#include <mutex>
#include <condition_variable>
#include <memory>
template<typename T>
class threadsafe_queue
{
private:
mutable std::mutex mut;
std::queue<std::shared_ptr<T> > data_queue;
std::condition_variable data_cond;
public:
threadsafe_queue()
{}
void wait_and_pop(T& value)
{
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk,[this]{return !data_queue.empty();});
value=std::move(*data_queue.front());
data_queue.pop();
}
bool try_pop(T& value)
{
std::lock_guard<std::mutex> lk(mut);
if(data_queue.empty())
return false;
value=std::move(*data_queue.front());
data_queue.pop();
}
std::shared_ptr<T> wait_and_pop()
{
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk,[this]{return !data_queue.empty();});
std::shared_ptr<T> res=data_queue.front();
data_queue.pop();
return res;
}
std::shared_ptr<T> try_pop()
{
std::lock_guard<std::mutex> lk(mut);
if(data_queue.empty())
return std::shared_ptr<T>();
std::shared_ptr<T> res=data_queue.front();
data_queue.pop();
return res;
}
bool empty() const
{
std::lock_guard<std::mutex> lk(mut);
return data_queue.empty();
}
void push(T new_value)
{
std::shared_ptr<T> data(std::make_shared<T>(std::move(new_value)));
std::lock_guard<std::mutex> lk(mut);
data_queue.push(data);
data_cond.notify_one();
}
};
线程安全队列—细粒度锁版、线程安全的查询表、线程安全链表—支持迭代器详细代码参见原书和随书代码。
第7章 无锁并发数据结构设计
本章主要介绍设计无锁并发数据结构、无锁结构中内存管理技术、对无锁数据结构设计的简单指导。
使用无锁结构的主要原因:将并发最大化。使用基于锁的容器,会让线程阻塞或等待;互斥锁削弱了结构的并发性。在无锁数据结构中,某些线程可以逐步执行。
使用无锁数据结构的第二个原因就是鲁棒性。
无等待的算法要比等待算法的复杂度高,且即使没有其他线程访问数据结构,也可能需要更多步骤来完成对应操作。但“无锁-无等待”代码虽然提高了并发访问的能力,减少了单个线程的等待时间,但是其可能会将整体性能拉低。
#include <atomic>
template<typename T>
class lock_free_stack
{
private:
struct node
{
T data;
node* next;
node(T const& data_):
data(data_)
{}
};
std::atomic<node*> head;
public:
void push(T const& data)
{
node* const new_node=new node(data);
new_node->next=head.load();
while(!head.compare_exchange_weak(new_node->next,new_node));
}
};
更多无锁设计的数据结构参见原书和随书代码。
第8章 并发代码设计
本章主要介绍了线程间划分数据的技术、影响并发性能的因素、性能因素是如何影响数据结构的设计、多线程代码中的异常安全、可扩展性、并行算法的实现。
当为多线程性能而设计数据结构的时候,需要考虑竞争(contention),伪共享(false sharing)和数据距离(data proximity)。这三个因素对于性能都有着重大的影响,并且你通常可以改善的是数据布局,或者将赋予其他线程的数据元素进行修改。
对于一个数组来说,访问连续的元素是最好的方式,因为这将会减少缓存的使用,并且降低伪共享的概率。改变划分方式往往能够提高性能,而不需要对基本算法进行任何修改。
1 尝试调整数据在线程间的分布,就能让同一线程中的数据紧密联系在一起。
2 尝试减少线程上所需的数据量。
3 尝试让不同线程访问不同的存储位置,以避免伪共享。
随着系统中核数的增加,性能越来越高(无论是在减少执行时间,还是增加吞吐率),这样的代码称为“可扩展”代码。理想状态下,性能随着核数的增加线性增长,也就是当系统有100个处理器时,其性能是系统只有1核时的100倍。
第9章 高级线程管理
本章主要介绍了线程池、处理线程池中任务的依赖关系、池中线程如何获取任务、中断线程。
在大多数系统中,将每个任务指定给某个线程是不切实际的,不过可以利用现有的并发性,进行并发执行。线程池就提供了这样的功能,提交到线程池中的任务将并发执行,提交的任务将会挂在任务队列上。队列中的每一个任务都会被池中的工作线程所获取,当任务执行完成后,再回到线程池中获取下一个任务。
创建一个线程池时,会遇到几个关键性的设计问题,比如:
可使用的线程数量,高效的任务分配方式,以及是否需要等待一个任务完成。
第10章 多线程程序的测试和调试
本章主要介绍了并发相关的错误、定位错误和代码审查、设计多线程测试用例及多线程代码的性能。
参考
[1] C++ Concurrency In Action
[2] C++ Concurrency In Action 源码
[3] C++并发实战 陈晓伟译



