
写在前面
Linux命令行与Shell脚本编程大全是一本不可多得的好书,值得多次精读并非常适合作手头工具书。下面是多次阅读的一些摘录整理,方便定期回顾查阅。
第一部分 Linux命令行
第一章 初始Linux Shell
1 Linux系统
Linux系统可划分为四部分:(1)Linux内核;(2)GNU工具;(3)图形化桌面环境;(4)应用软件。下图是Linux系统的一个基本结构框图。
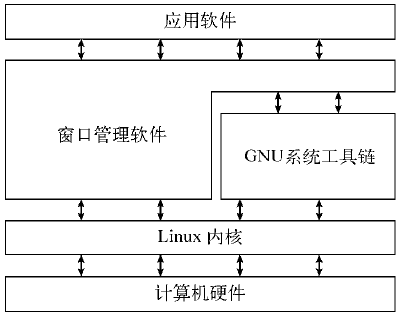
2 深入探究Linux内核
① Linux内核主要负责四种功能:(1)系统内存管理;(2)软件程序管理;(3)硬件设备管理;(4)文件系统管理。
② 软件程序管理:一些Linux发行版通过使用/etc/inittab表来管理自动启动进程,另外一些通过/etc/init.d目录下的脚本来管理自启动(例如Ubuntu),这些脚本通过/etc/rcX.d目录下的入口启动,X代表启动运行级(有5个,1代表单用户模式,3是标准启动,5会启动X Window系统)
③ 硬件设备管理:Linux系统将硬件设备当成特殊的文件,称为设备文件。设备文件有3种分类:字符型设备文件,块设备文件,网络设备文件。
3 GNU工具
① GNU coreutils软件包有三部分组成:(1)用于处理文件的工具;(2)用于操作文本的工具;(3)用于管理进程的工具。
② GUN/Linux shell是一种特殊的交互式工具,为用户提供了启动程序、管理文件及进程的途径。shell的核心是命令行提示符。
第二章 走进Shell
主要讲了如何进入命令行环境。
第三章 基本的Bash Shell命令
1 下图是常见Linux目录名称

2 ls命令
ls -F #可区分文件和目录
ls -a #显示所有文件,包括隐藏文件
ls -R #递归
ls -l #显示长列表,每一行包含了文件的:1 文件类型(d:目录,-:文件,l:链接,c:字符型文件,b:块设备,n:网络设备);2 文件权限;3 硬链接数;4 文件属主; 5 文件属组; 6 文件大小; 7 文件上次修改时间; 文件名或目录名
ls -l f[!a]ll #可通过文件扩展匹配来过滤输出列表
ls -i file #查看file的inode编号
3 链接文件
ln -s data_file sl_data_file #创建符合链接,又称软链接
ln code_file hl_code_file #创建硬链接
4 创建目录
mkdir -p a/b/c #同时创建多个目录和子目录
5 查看文件内容
file my_file #查看my_file类型
cat -n my_txt #查看my_txt文本并加上行号
cat -b my_txt #只给有文本的行加行号
tail -n 2 my_txt #只显示文件最后两行
head -5 my_txt
第四章 更多的Bash Shell命令
1 监测程序
① 探查进程,GNU ps命令支持3种不同类型的命令行参数:(1)Unix风格,单破折线;(2)BSD风格,不加破折线;(3)GNU风格,双破折线。下图是Unix风格的ps命令参数表。

② 常用ps -ef来产看进程信息,UID:启动进程的用户;PID:进程的进行ID;PPID:父进程的进程号;C:CPU利用率;STIME:进程启动的系统时间;TTY:进程启动时的终端设备;TIME:运行进程累计CPU时间,CMD:启动程序的名称;
③ 实时监测进程:top,PID:进程的ID;USER:属主;PR:进程的优先级;NI:谦让度值;VIRT:占用虚拟内存总量;RES:占用物理内存总量;SHR:和其他进程共享内存总量;S:进程的状态;COMMAND:启动进程的程序名。
④ 结束进程
kill 3940 #发出TERM信号,结束PID为3940的进程
kill -s HUP 3940 # -s参数指出指定其他信号
killall http* #通过进程名来结束进程
2 监测磁盘
① 挂载
mount -t type device directory #基本格式,type可指定vfat,ntfs,iso9660等
② 下图是mount命令的参数表。


③ umount,卸载,注意没有n
④ df,某个设备上还有多少磁盘空间
df -h
⑤ du,显示某个特定目录(默认情况是当前目录)的磁盘使用情况
du -chs # -c显示所有已列出文件的总大小,-h易读格式,-s显示每个输出参数的总计
3 处理数据文件
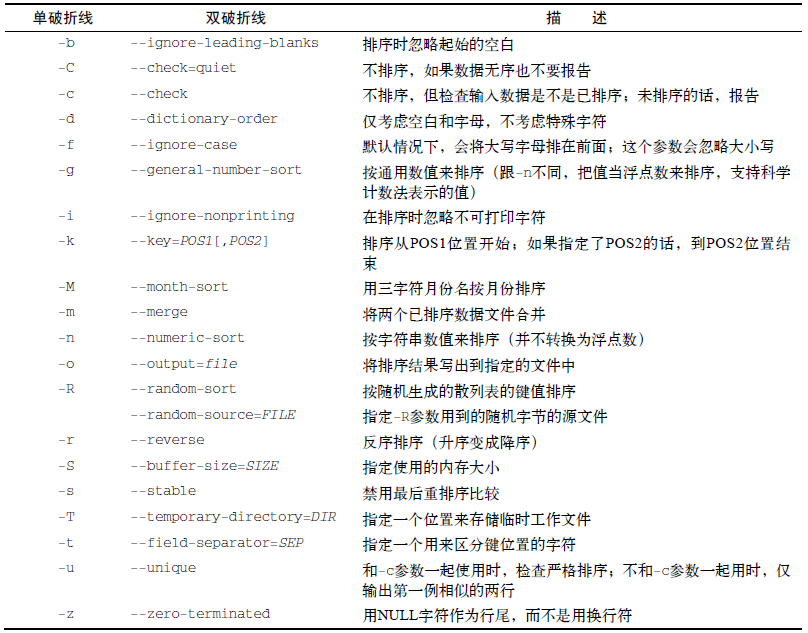
① 排序数据,sort,下图是sort命令参数表。
② 搜索数据,grep
grep [options] pattern [file] #基本格式
grep -v t file # 反向搜索,输出不匹配t的行
grep -n t file #列出行号
grep -c t file #统计
grep -e t -e s file #指定多个匹配模式
③ 压缩数据,bzip2:.bz2,compresss:.Z,gzip:.gz,zip:.zip
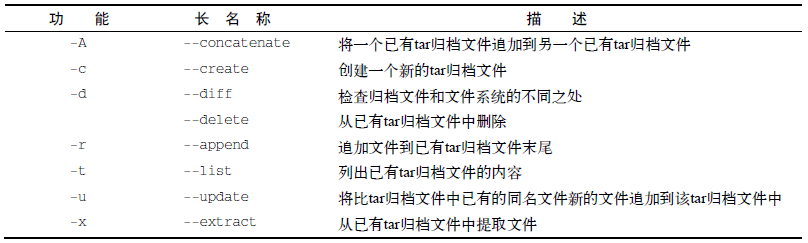
④ 归档数据,tar
tar function [options] object1 object2... #基本格式
tar -cvf test.tar test1/ test2/ #归档
tar -tf test.tar #列出不提取
tar -xvf test.tar #提取
tar -zxvf test.tgz #解压提前
功能function参数表和命令选项options表如下。

第五章 理解Shell
1 Shell父子关系
① 命令之间加入分号,命令依次执行。
② 将命令包含在括号里,就命令列表就会成为进程列表,会生成子进程在其中执行。另一种命令分组是将命令放入花括号,命令尾部加入分号,花括号中的命令列表并不创建子shell。
③ 命令后加&会置入后台执行。同样可以使用coproc实现,coproc(协程)同时做两件事:后台生子shell,并在zishell中执行命令。相当于进程列表后加&。
2 理解Shell内建命令
① 外部命令是存在于bash shell之外的程序,不是shell的一部分,通常位于/bin、/sbin、/usr/bin、/usr/sbin中。可以使用type来了解命令是否是内建的。type -a command可以显示command的全部实现。
② 历史,history,命令历史记录保存在用户主目录的隐藏文件.bash_history中。
history #查看历史记录
history -a #强制写入.bash_history文件,通常只有退出shell时才会写入
!! #执行刚执行的命令
!20 #执行编号为20的命令
③ 命令别名,alias
alias -p #查看当前可用别名
alias li='ls -li'
第六章 使用Linux环境变量
1 什么是环境变量
① 查看变量
env #查看全局变量
printenv #查看全局变量,也可以使用printenv HOME显示个别环境变量的值
set #显示某个特定进程设置的所有环境变量,包括局部变量、全局变量、用户自定义变量
② 设置变量
my_variable="Hello World" #设置局部用户定义变量,子进程不可以访问,因为字符串含有空格,所以使用引号,注意变量名、等号和值之间没有空格
expport my_variable #设置为全局变量,子进程可以访问但修改对父进程无效,注意变量名前不需要加$
unset my_variable #删除环境变量,不加$。一般,操作变量不使用$,用到变量才使用$,printenv除外。
2 定位系统环境变量
① Bash检查的启动文件取决于启动Bash Shell的方式。启动的方式一般有三种:(1)登录时作为默认登录shell;(2)作为非登录shell的交互式shell;(3)作为运行脚本的交互式shell。
② 登录shell会从5个不同的启动文件里读取命令:(1)/etc/profile;(2)HOME/.bash_profile;(3)HOME/.bashrc;(4)HOME/.bash_login;(5)HOME/.profile。其中(1)是默认的主启动文件;(2)(4)(5)会按照顺序运行第一个被找到的文件,其余的则被忽略。
③ 交互式shell进程,如果bash是作为交互式shell启动的,它不会访问/etc/profile,只会检查用户HOME目录中的.bashrc文件。.bashrc文件有两个作用,一是查看/etc目录下的bashrc文件,二是为用户提供一个定制别名和私有函数的地方。
④ 非交互是shell,当shell启动一个非交互式shell时,它会检查BASH_ENV环境变量来查看要执行的启动文件。
⑤ 环境变量持久化,放入/etc/profile并不是一个好主意,升级发行版时这个文件会更新,可能丢失设置。最好是在/etc/profile.d目录中创建一个以.sh结尾的文件,把所有新的或修改过的全局变量放在这个文件里。大多数发行版里,存储个人用户永久性bash shell变量的地方是$HOME/.bashrc。
3 数组变量
mytest=(one two three four five) #设置数组变量
echo $mytest #只会显示第一个值
echo ${mytest[2]} #three
echo ${mytest[*]} #显示整个数组变量
mytest[2]=seven #改变
第七章 理解Linux文件权限
1 添加用户,useradd
useradd -m test #创建test用户并为其创建HOME目录,useradd其他参数用时可以具体查看
2 删除用户,userdel,默认情况只会删除/etc/passwd文件中的用户信息,不会删除该账户任何文件,加上-r参数会删掉HOME目录及邮件目录。
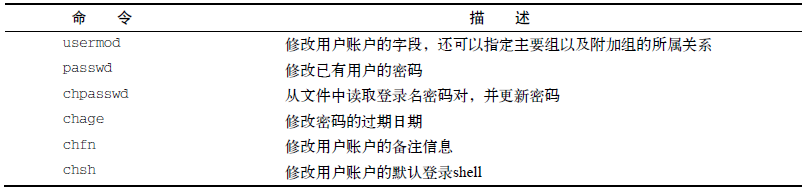
3 修改用户,下图是一些用户账户修改工具
4 Linux组
/usr/sbin/groupadd shared #创建shared新组
/usr/sbin/usermod -G shared test #将test加入到shared组
/usr/sbin/groupmod -n sharing shared #改变祖名,-g改变组GID
5 设置默认文件和目录权限,umask。对于文件来说,全权限是666(所有用户都有读写);对于目录来说,全权限是777(所有用户都有读写执行权限)。
umask 026 #设置默认新建文件权限为640,-rw-r-----,默认目录权限751,drwxr-x--x
6 改变权限,chmod
chmod options mode file #基本格式
chmod 760 file #改变权限方法一
chmod [ugoa][+-=][rwxXstugo] #改变权限方法二,设置上的权限选项中X:如果对象是目录或者它已有执行权限,赋予执行权限;s:运行时重新设定UID或GID;t:保留文件或目录;u:将权限设置的跟属主一样
7 改变所属关系,chown和chgrp
chown options owner[.group] file #基本格式
chown dan.shared file #同时改变file的属主和属组
chgrp shared file #g改变文件数组
8 共享文件,想让其他人能访问文件要么改变其他用户所在安全组的访问权限,要么给文件分配一个包含其他用户的新默认属组。但在大范围环境中创建文档并共享,这样做会很繁琐,有一种简单的方法可以解决。
mkdir testdir
chgrp shared testdir
chmod g+s testdir #将SGID和SUID置位,目录的SGID置位可使得目录中新建文件都用shared作为默认属组,而不是用户的默认属组。
第八章 管理文件系统
1 Linux文件系统
① ext和ext2是基本的文件系统,为了提高安全性出现了ext3,ext4等日志文件系统,在系统崩溃或断电后,日志文件系统下次会读取日志文件并处理上次留下的未写入数据。文件系统日志方法有三种:(1)数据模式,索引节点和文件都会被写入日志,丢失数据风险低;(2)有序模式,只写入索引节点数据,数据写入成功后才删除;(3)回写模式,只写入索引,但不控制文件数据何时写入,风险高。
② 创建分区fdisk。
③ 创建文件系统mkfs.ext3,mkfs.ext4等等。
④ 文件系统的检查和恢复fsck。
2 逻辑卷管理
① 逻辑卷管理环境的基本布局如下图所示。
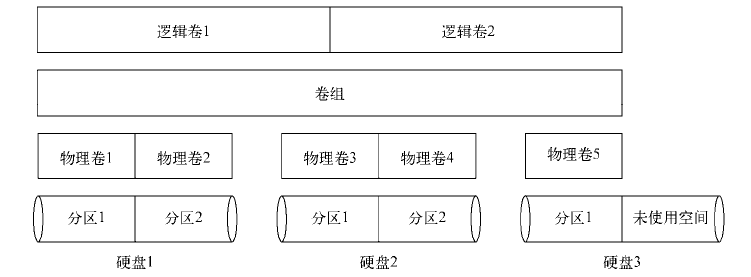
② Linux LVM允许你用简单的命令行管理一个完整的逻辑卷管理环境。
a 首先用fdisk交互t命令改变分区类型,改为8e类型(表示该分区会被用作Linux LVM系统的一部分)。
b 使用分区来创建实际的物理卷:sudo pvcreate /dev/sdb1,可以使用sudo pvdisplay /dev/sdb1命令来查看进度显示已创建的物理卷列表
c 从物理卷中创建一个或多个卷组: sudo vgcreate Vol1 /dev/sdb1,可用sudo vgcreate Vol1 /dev/sdb1查看新创建卷组细节。
d 创建逻辑卷:sudo lvcreate -l 100%FREE -n lvtest Vol1,可用sudo lvdisplay Vol1查看细节。
e 创建文件系统:sudo mkfs.ext4 /dev/Vol1/lvtest,创建之后可以使用sudo mount /dev/Vol1/lvtest /mnt/my_partition将其挂载到虚拟目录里。
③ Linux LVM的好处是能够动态修改文件系统,常见的有vgchange, vgremove, vgextend, vgreduce, lvextend, lvreduce等命令。
第九章 安装软件程序
1 基于Debian的Linux发现版使用dpkg工具作为命令行与PMS(软件包管理系统)的接口。dpkg工具的一个前端是aptitude,提供了处理dpkg格式软件包的简单命令行选项。
2 基于Red Hat的Linux发行版以rpm工具为基础,命令行下用yum安装和管理软件包。openSUSE发行版采用zypper来管理软件,Mandriva发行版采用urpm管理。
第十章 使用编辑器
介绍了多种编辑器的用法,本人喜欢用VIM,可移步这里学习VIM的快捷键。
第二部分 Shell脚本编程基础
第十一章 构建基本脚本
1 Shell脚本中#用作注释行,shell并不会处理,shell脚本文件中第一行除外,#!/bin/bash会告诉shell用哪个shell运行脚本。
2 显示消息,使用echo。echo命令可以使用单引号或双引号来划定文本字符串,如果在字符串中用到了它们,需要在文本中使用一种引号,而用另外一种来将字符串划定起来。
3 用户变量可以是任何字母/数字或下划线组成的文本字符串,长度不超过20个。注意:(1)用户变量区分大小写;(2)在变量等号和值之间不能出现空格。
4 命令替换。有两种方法可以将命令输出赋给变量:(1)反引号字符`;(2)$()格式。
testing=`date` #方法一
testing=$(date +%y%m%d) #方法二
5 重定向。>输出重定向,>>追加输出重定向,<输入重定向,<<内联输出重定向。使用内联输出重定向时,必须指定一个文本标记来划分输入数据的开始和结尾,任何字符都可以作为文本标记,但开始结尾需要使用同一个标记。
# wc命令可以统计数据中的文本,默认情况下会输入文本的行数、词数、字节数。
wc << EOF
test string 1
test string 2
EOF
6 管道|。不要以为管道链接的命令会依次执行,系统实际上会同时执行,第一个命令产生输入的同时会被立即送给第二个命令处理。
7 执行数学运算。途径有两种:(1)expr命令;(2)使用美元符和方括号将数学表达式包起来。但这两种只支持整数运算,浮点运算使用bc。
① expr命令,expr支持的命令操作符如下表。
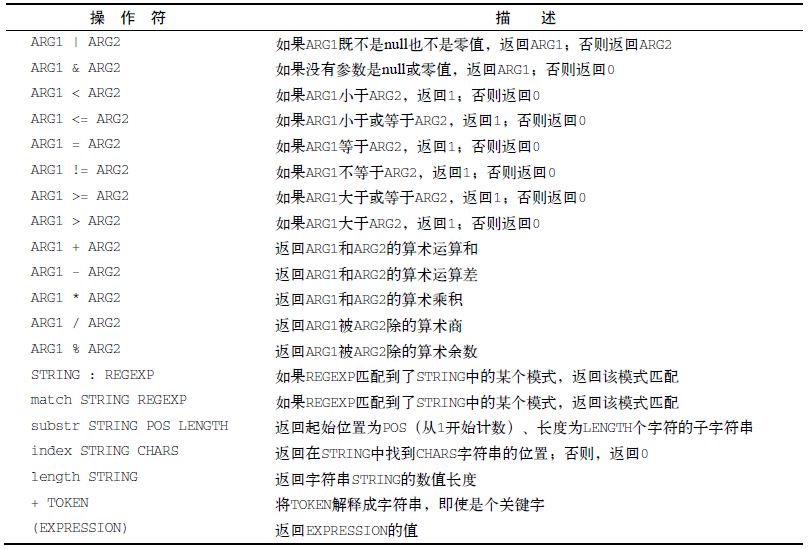
expr 1+5
expr 5\*2 #容易被shell错误解释的字符,需要用转移字符反斜线将其标注来
② 使用美元符号和方括号
val=$[[ 3*5 ]]
③ 浮点解决方案bc
#基本用法
bc -q #-q选项可以不显示bash计算器冗长的欢迎信息
scale=4 # 设置计算结果中保留的小数,默认是0
val=4/5
quit
#脚本中使用
val=$(echo "scale=4;3.44/5" | bc) #适用于较短运算
val=$(bc <<EOF
options
statements
expressions
EOF
) #适用于大量运算
8 退出脚本
date
echo $? #$?变量会保存上个已执行命令的退出状态码,为0~255的整数值,0表示成功执行
exit 5 #默认情况下脚本会用脚本中的最后一个命令的退出码退出,exit命令可以改变退出码状态
第十二章 使用结构化命令
1 使用if。if语句会运行if后面的命令,如果该命令的退出状态码是0,位于then后面的命令就会被执行。
if command1
then
commands
elif command2
then
commands
else
commands
fi
2 使用test或方括号进行条件测试。test提供了if语句测试不同条件的途径,如果test的条件成立,test就会退出并返回状态码0。使用方括号无需声明test。
#使用test
if test condition #如果不写test后的condition部分,它会以非零的状态码输出,if判断不成立。
then
commands
fi
#使用方括号
if [ condition ] #注意方括号前后需要有空格
then
commands
fi
条件测试可以判断三类条件:数值比较、字符串比较和文件比较,三类条件支持的功能对应如下图。



需要注意:(1)使用大于号和小于号进行字符串比较的时候必须转义,否则会把它们当作重定向符号;(2)比较测试中使用的是标注的ASCII顺序,大写字母被认为小于小写字母,sort命令使用的是系统本地化语音设置中的排序顺序,小写字母大于大写。
3 符合条件测试:[ condition1 ] && [ condition2 ]和[ condition1 ] || [ condition2 ]。
4 if-then的高级特性。
① 用于数学表达式的双括号。双括号允许在比较的过程中使用高级数学表达式,除去test支持的标准数学运算符外,双括号支持val++,val--,++val,--val,**,!,~,<<,>>,&,|,&&,||。
if (( val1**2 > 90 ))
then
(( val2=$val1**2 ))
echo "The square of $val1 is $val2"
fi
② 用于高级字符串处理功能的双方括号。双方括号提供了针对字符串比较的高级特性,除标准字符串比较,它提供了模式匹配。
if [[ $USER == r* ]]
then
echo "Hello $USER"
else
echo "Sorry, I do not know you"
fi
5 case命令
case variable in
pattern1 | pattern2) commands1;;
pattern3) commands2;;
*) default commands;;
esac
第十三章 更多的结构化命令
1 for命令
#基本格式
for var in list
do
commands
done
#例1 读取列表中复杂的值
for test in I don\'t know if "this'"ll work
do
echo "word:$test"
done
#例2 更改字段分隔符
IFS.OLD=$IFS
IFS=$'\n' #默认是空格,现在将内部字段分隔符IFS设为换行符。设置多个只需要将它们在赋值行串起来IFS=$'\n':;
for state in $(cat states.txt)
do
echo "Visit beautiful $state"
done
IFS=$IFS.OLD
#例3 用通配符读取目录
for file in /home/lxs/*
do
if [ -d "$file"]
then
echo "$file is a directory"
elif [ -f "$file" ]
then
echo "$file is a file"
fi
done
#例4 C语言风格的for命令
for (( i=1;i<=10;i++ ))
do
echo "The next number is $i"
done
2 while命令
while test command #或者while [ condition ]
do
other comands
done
#使用多个测试命令,注意每个测试命令一行,每次迭代所有的测试命令都会被执行
var1=0
while echo $var1
[ $var1 -ge 0]
do
echo "This is inside the loop"
var1=[ $var1-1 ]
done
3 until命令,与while工作方式相反,until命令要求你指定一个通常返回非零状态码的测试命令,只有退出码不为0时,才会执行循环中的命令。
until test commands #或者until [ condition ]
do
other commands
done
4 控制循环,break和continue,与编程中的用法一样,但可以使用break n或者continue n来跳出或继续哪一级循环。
5 循环输出和输入,可使用重定向
#输出重定向
for file in /home/lxs/*
do
if [ -d "$file"]
then
echo "$file is a directory"
elif [ -f "$file" ]
then
echo "$file is a file"
fi
done >output.txt
#输入,数据从文件中送入while命令。批量添加用户
input="users.csv"
while IFS=',' read -r userid name
do
echo "adding $userid"
useradd -c "$name" -m $userid
done <"$input"
第十四章 处理用户输入
1 位置参数是标准的数字:$0是程序名,$1是第一个参数,$2是第二个参数,依此类推,直到第九个$9,多于个需要以${10}这种形式。
name=$(bashname $0) #bashname命令会返回不包含路径的脚本名,$0带有路径
2 特殊参数变量。$#含有脚本运行是携带的命令行参数的个数;$*变量会将命令行上提供的所有参数当作一个单词保存;$@变量会将命令行上提供的所有参数当作同一字符串中的多个独立的单词。
3 移动变量。使用shift命令,默认情况下它会将每个参数变量向左移动一个位置。所以$3的值会移到$2。
4 处理选项。最好使用getopts命令。命令的格式getopts optstring variable。有效的选项字母都会列在optstring中;如果选项字母要求有个参数,就在其后加一个冒号;去掉错误信息的话,可以在optstring之前加一个冒号。getopts命令将当前参数保存在命令行中定义的variable中。getopts命令会用到两个环境变量,如果选项需要跟一个值,OPTARG变量就会保存这个值,OPTIND环境变量保存了参数列表中getopts正在处理的参数位置。
#test.sh
while getopts :ab:cd opt
do
case "$opt" in
a) echo "Found the -a option" ;;
b) echo "Found the -b option, with value $OPTARG" ;;
c) echo "Found the -c option" ;;
d) echo "Found the -d option" ;;
*) echo "Unknown option: $opt";;
esac
done
shift $[ $OPTIND-1 ] #处理每个选项时,OPTIND都会增一
count=1
for param in "$@"
do
echo "Parameter $count: $param"
count=$[ $count+1 ]
done
#测试test.sh:./test.sh -a -b test1 -d test2 test3 test4
5 将选项标准化。常用的Linux命令选项见下表。

6 获得用户输入,read。read命令会从标准输入或另外一个文件描述符中接受输入。
read -p "Please enter your age: " age #如果不指定存放的age变量,read会将收到的任何数据放进REPLY中
days=$[ $age*365 ]
echo "That makes you over $day old!"
read -t 5 -n1 -p "Do you want to continue [Y|N]?" answer #-t设置超时,-n1设置接受单个字符后退出
read -s -p "Your password:" pass #隐藏方式读取
cat test.txt | while read line #从文件中读取
第十五章 呈现数据
1 标准文件描述符。Linux系统将每个对象当作文件来处理,其用文件描述符来标识每个对象。文件描述符时一个非负数,可以唯一标识会话中打开的文件。每个进程最多可以有九个文件描述符,出于特殊目的,bash shell保留了前三个文件描述符(0,1和2),如下表所示。

2 重定向错误和数据
ls -al ./ 2>stderr.log 1>stdout.log
ls -al ./ &> all.log # &>符号会将所有的输出都发送到同一位置
3 脚本中重定向输出
echo "This is an error message" >&2 #脚本中生成的错误信息重定向到STDERR文件描述符。
exec 1>testout #永久重定向,exec会告诉shell在脚本执行期间重定向某个特定文件描述符
4 脚本中重定向输入
exec 0<testfile #shell从文件testfile中获得输入,而不是STDIN
5 创建自己的重定向,shell中最多可以有9个打开的文件描述符,其他6个从3~8的文件描述符均可做输入输出重定向。
#创造输出文件描述符
exec 3>&1 #将文件描述符3重定向到描述符1的当前位置,也就是STDOUT
exec 1>testout #将STDOUT重定向到文件
echo "This should store in the output file"
echo "along with this line"
exec 1>&3 #将STDOUT重定向到3的当前位置
echo "Now things should be back to normal"
#创造输入文件描述符
exec 6<&0
exec 0<testfile
...
exec 0<&6
#关闭文件描述符
exec 3>&-
6 列出打开的文件描述符
/usr/sbin/lsof -a -p $$ -d 0,1,2 #-a选项用来对其他两个选项的结果执行布尔AND运算,-p允许指定进行ID(PID),-d允许指定要显示的文件描述符编号,特殊环境变量$$代表进程的当前PID
7 可通过重定向到/dev/null来阻止命令输出,丢掉数据,/dev/null也常被用来快速清除现有文件的数据:cat /dev/null >testfile。
8 创建临时文件或目录
tempfile=$(mktemp test.XXXXXX) #mktemp命令会用6个字符替换这6个X,可以创建多个临时文件而不会重复
exec3>$tempfile
echo "This is the first line" >&3
exec 3>&-
cat $tempfile
rm -f $tempfile 2>/dev/null
mktemp -t test.XXXXXX #-t命令会强制在/tmp文件夹中创造临时文件,mktemp此时返回全路径而不是单个文件名
mktemp -d dir.XXXXXX #创建临时目录
9 记录消息,tee命令可以同时将输出发送到显示器和日志。
date | tee testfile
date | tee -a testfile #追加
10 实例
#将命令行参数指定的数据文件转化为sql语句
outfile='members.sql'
IFS=','
while read lname fname address city state zip
do
cat >> $outfile << EOF #此语句有两个重定向,将cat命令的输出追加到outfile变量指定的文件,cat命令不再取自标准输入,而是重定向到脚本中存储的数据,EOF时数据起止的标记
INSERT INTO members (lname,fname,address,city,state,zip) VALUES ('$lname','$fname','$address','$city','$state','$zip');
EOF
done <${1}
第十六章 控制脚本
1 Linux系统和应用程序可以生成超过30个信号,下表中时编程时会遇到的最常见的Linux系统信号。默认情况下bash shell会忽略收到的SIGOUTIT和SIGTRERM信号。


2 Ctrl+C会产生SIGINT信号,停止shell中当前运行的进程;Ctrl+Z会产生SIGTSTP信号,暂停进程。
3 捕获信号,trap。如果脚本收到了trap命令中列出的信号,该信号不再用shell处理,而是交由本地处理。
trap commands signals #基本格式
trap "echo 'Sorry! I have trapped Ctrl-C'" SIGINT
trap "echo Goodbye..." EXIT #捕获退出信号
trap -- SIGINT #删除已设置号的捕获
4 以后台模式运行脚本,命令后加&即可。如果想要让脚本一直以后台模式运行到结束,即使你退出了终端会话,此时需要使用nohup命令来实现。
nohup ./test.sh &
5 作业控制,jobs。jobs常用的命令参数如下表。jobs命令输出中,带+号的会被当作默认作业,带减号的作业是下一个默认作业。通过bg n或fg n命令来置入后台或前台运行。

6 调整谦让度。调度优先级是个整数值,从-20(最高优先级)到+19(最低优先级)。默认情况下,bash shell以优先级0来启动所有进程。
nice -n -10 ./test.sh #注意提高优先级不能用普通账户操作,需要用root用户操作,否则并不能设置成功
renice -n 10 -p 5055 #改变PID为5055的程序的优先级
7 定时运行作业。
① 用at命令来计划执行作业。at可识别多种不同的时间格式,例如10:15,10:15PM,now,noon,midnight,MMDDYY,Jul 4,当前时间+25 min,明天10:15PM,10:15+7天等等。 at默认使用sendmail作为应用程序,使用用户的电子邮件作为STDOUT和STDEPR。使用at时如不想信息发送邮件需要使用重定向,或者加入-M选项来屏蔽作业产生的输入信息。
at [-f filename] time #基本格式,可以用-f参数指定用于读取命令(脚本文件)的文件名
atq #查看系统中有哪些作业在等待
atrm 18 #删除等待中的作业
② 安排需要定期执行的脚本,cron表。corn表允许你用特定值、取值范围(例如1~5)、或者通配符(星号)来指定条目。
min hour dayofmonth month dayofweek command #基本格式
15 10 * * * command #每天的10:15允许命令
15 10 * * * /home/lxs/test.sh >test.out
crontab -l #列出已有的cron时间表
crontab -e #为cron时间表添加条目
执行时间要求不高的话可以将脚本放入/etc/cron.hourly(daily monthly weekly)等目录下。cron程序的唯一问题时它假定系统7*24小时运行的,如果处于关机状态,程序并不会运行。anacron可以解决该问题。如果anacron知道某个作业错过了执行时间,它会尽快运行该作业。anacron程序只会处理cron目录的程序,但其不会处理执行时间需要小于一天的脚本(不处理/etc/cron.hourly下的脚本)。
period delay identifier command #anacron的基本格式,period单位时天,delay指定系统启动后anacron程序需要等待多少分钟再开始运行错过的脚本。
第三部分 高级Shell脚本编程
第十七章 创建函数
1 基本的脚本函数。
#创建方式1
function func1 { #注意空格
echo "This is an example of a function 1"
}
#创建方式2
func2() { #注意空格
echo "This is an example of a function 2"
}
#使用函数
func1
func2
2 返回值。默认情况下函数退出状态码时函数中最后一条命令返回的退出状态码。bash shell使用return命令来退出函数并返回特定的状态码(0~255).要返回任意类型的函数输出,可将输出保存到shell变量。
function db1 {
read -p "Enter a value: " value
echo $[ $value*2 ]
}
result=$(db1)
3 向函数传递参数。函数无法直接获取脚本在命令行中的参数值。
function func {
echo $[ $1*$2 ]
}
if [ $# -eq 2 ]
then
value=$(func $1 $2)
echo "The result is $value"
else
echo "Usage: test a b"
fi
4 在函数中处理变量。无需在函数中使用全局变量,函数内部使用的任何变量都可以被声明为局部变量。要实现这一点只需要在变量声明的前面加上local关键字。
function func {
local temp=$[ $value+5 ]
result=$[ $temp*2 ]
}
5 数组变量和函数。如果你试图将数组变量作为函数参数,函数追取数组变量的第一个值,要解决这个问题,你必须将该数组变量的值分解为单个的值,然后将这些值作为函数参数使用。在函数内部,可以将所有的参数重新组合成一个新的变量。下面是一个例子。
function testit {
local newarray
newarray=($(echo "$@"))
echo "The new array value is: ${newarray[*]}"
}
myarray=(1 2 3 4 5)
echo "The original array is ${myarray[*]}"
testit ${myarray[*]}
从函数里向shell脚本传回数组变量也用类似的方法。函数用echo语句来按正确的顺序输出单个数组值,然后脚本再将它们重新放进一个新的数组变量里。
function arraydblr {
local origarray
local newarray
local elements
local i
origarray=($(echo "$@"))
newarray=($(echo "$@"))
elements=$[ $#-1 ]
for(( i=1;i<=$elements;i++ ))
{
newarray[$i]=$[ ${origarray[$i]}*2 ]
}
echo ${newarray[*]}
}
myarray=(1 2 3 4 5)
echo "The original array is: ${myarray[*]}"
arg1=$(echo ${myarray[*]})
result=$(arraydblr $arg1)
echo "The new array is: ${result[*]}"
6 函数递归
function factorial {
if [ $1 -eq 1]
then
echo 1
else
local temp=$[ $1-1 ]
local result=$(factorial $temp)
echo $[ $result*$1 ]
fi
}
7 创建库。使用函数库的关键在于source命令,会在当前shell上下文中执行命令,而不是创建一个新shell。source有个快捷的别名,称作点操作符,要想在shell脚本中运行myfuncs库文件,只需添加下面这行:
. ./myfuncs
第十八章 图形化桌面环境中的脚本编程
该章讲了可以让交互式脚本更友好的图形化桌面脚本编程。用到了随时翻阅即可。
第十九章 初识Sed和Gawk
1 sed编辑器被称作流编辑器,只对数据流进行一遍处理就可以完成编辑操作。sed命令选项如下表所示。

sed options script file #基本格式
echo "This is a test" | sed 's/test/big test/'
sed -e 's/brown/green/; s/dog/cat/' data.txt #在命令行使用多个编辑器命令
sed -e ' #如不想使用分号,可使用下面的多行形式
s/brown/gree/
s/dog/cat/' data.txt
sed if script.sed data.txt #从文件中读取编辑器命令
2 gawk程序。其可以提供一个类编程环境来修改和重新组织文件中的数据。可定义变量保存数据;可使用算术和字符串操作处理数据;可使用结构化编程概念;可通过提取数据文件中的数据元素,将其重新排列或格式化,生成格式化报告。gawk选项如下表所示。

gawk options program file #基本格式
echo "My name is Rich" | gawk '{$4="Christine"; print $0}' #$0代表整个文本行,$1代表第一个数据字段
gawk -F: 'print $1' /etc/passwd #指定:作为分隔符
gawk 'BEGIN {print "The data File Contents:"}' #处理数据前运行
{print $0}
END {print "End of File"}' data.txt #处理数据后运行
可将内容放入到小程序脚本文件,用gawk -f 指定调用。
3 sed编辑器基础
① 替换标记。默认情况下只替换每行中出现的第一处,额我i替换不同地方出现的文本,必须使用替换标记。有四种替换标记:(1)数字:表明新文本将替换第几处模式匹配的地方;(2)g:表示新文本会替换所有匹配的文本;(3)p:表示原先行的内容要打印出来;(4)w file:将替换的结果写入到文件。
sed 's/test/trial/w test.txt' data.txt
② 替换字符。sed编辑器允许选择其他字符来作为替换命令中的字符串分隔符。
sed 's!/bin/bash!/bin/csh!' /etc/passwd #可避免写sed 's/\/bin\/bash/\/bin\/csh/' /etc/passwd这样的命令
③ 使用地址。sed编辑器中有两种形式的行寻址:(1)以数字形式来表示行区间;(2)以文本模式来过滤出行。
sed '2,$s/dog/cat/' data.txt # 命令作用到从某行开始的所有行
sed '/Samantha/s/bash/csh/' /etc/passwd #文本模式过滤,允许指定文本模式类似过滤出命令要作用的行
④ 删除行
sed '3,5d' data.txt #删除3到5行
sed '/number 1 /d' data.txt #删除文本模式匹配的行
sed '/number 1/,/number 3/d' #删掉匹配模式number 1到number 5之间的行,如果只匹配到number 1会一直删到文末。
⑤ 插入和附加文本。插入i命令会在指定行前增加一个新行;附件a命令会在指定行后增加一个新行。
echo "Test Line2" | sed 'i\Test Line 1'
sed '3i\This is an inserted line.' data.txt #寻址插入,要插入或附加多行,需要在每一行使用反斜杠。
⑥ 修改行c。
sed '\numberr3 c\This is a changed line of text.' data.txt
⑦ 转换命令y是唯一可以处理单个字符的sed编辑器命令。转换命令是个全局命令,会对找到的所有指定字符自动进行转换。
echo "This 1 is a test of 1 try." | sed 'y/123/456/' #123与456一一对应转换
⑧ 回顾打印。p用来打印文本行;等号用来打印行号;l用来列出行。
sed -n '/number 3/p' data.txt #-n选项可以禁止输出其他行,只打印包含匹配文本模式的行。
sed '=' data.txt #打印行号
sed -n 'l' data.txt #列出行可以打印数据流中的文本和不可打印的ASCII字符。
⑨ 从文件读取数据。
sed '3r data1.txt' data.txt #从文件data1.txt中读取数据插入到寻找到的行后
第二十章 正则表达式
1 正则表达式类型。Linux系统中有两种流行的正则表达式引擎:(1)POSIX基础正则表达式BRE引擎;(2)POSIX扩展正则表达式ERE引擎。大多数Linux工具至少符合BRE引擎规范,sed只符合BRE规范,gawk用ERE引擎。
2 基础正则表达式BRE
① 正则表达式模式都区分大小写,只会匹配大小写也相符的模式。
② 特殊字符。包括.*[]^${}+?|(),当作普通文本需要用反斜线进行转义。
③ BRE特殊字符组,见下表。

3 扩展正则表达式ERE
① ?+{}|()属于ERE中的特殊符号,BRE不支持。
② gawk使用正则表达式间隔时,必须使用--re-interval命令选项。
第二十一章 Sed进阶
1 多行命令。sed包含了三个可用来处理多行文本的命令:(1)N:将数据流中的下一行加进来创建一个多行组来处理;(2)D:删除多行组中的一行;(3)P:打印多行组中的一行。
sed '/header/{n ; d}' data.txt #小写的n命令会告诉sed编辑器移动到数据流中的下一行。该行命令删除header所在行的下一行
sed '/first/{N ; s/\n/ /}' #大写的N命令会将下一行文本行添加到模式空间中已有的文本后。该行命令查找含有单词first的行,找到行用N命令将下一行合并到first行,将换行符替换为空格。
# data.txt
On Tuesday, the Linux System
Administrator's group meeting will be held.
#将System Administrator替换为 Desktop User的正确姿势为
sed '
s/System Administrator/Desktop User/
N
s/System\nAdministrator/Desktop\nUser/
'data.txt
sed '/^$/{N ; /headers/D}' data.txt #查找空白行,然后N将下一行文本添加到模式空间,如果新模式空间含有单词headers,D命令会删除模式空间中第一行(空白行)。
sed -n 'N ; /System\nAdministrator/P' data.txt #多行匹配出现时,P命令只打印模式空间中第一行。
2 保持空间。模式空间时一块活跃的缓冲区,在sed编辑器执行命令时它会保存待检查的文本。sed编辑器有另一块称作保持空间的缓冲区域,在处理模式空间中的某些行时,可以用保持空间来临时保存一些行。有5条命令可以用来操作保持空间,如下表。

3 排除命令。感叹号!可用来让原本起作用的命令不起作用。
sed -n '{1!G ; h ; $p}' data.txt #翻转文本,第一行不执行G,然后执行h,不是最后一行不执行p,然后执行G,执行h...一直到处理完毕,实现翻转文本。
4 改变流。可使用分支b命令和测试t命令来改变sed编辑器执行流程。
① 命令b,根据地址、地址模式或地址区间进行跳转排除一整块命令。
#地址区间跳转
sed '2,3b ; s/This is/ Is this ; s/line./test?' data.txt
#地址模式,标签跳转
sed '{/first/b jump1 ; s/This is the/No jump on/ #如果文本行出现了first就调到标签为jump1的行
:jump1
s/This is the/Jump here on/}' data.txt
② 测试t,根据替换命令的结果跳转到某个标签。如果替换命令成功匹配并替换了一个模式,测试命令就会跳到指定的标签。如果替换命令未能匹配指定的模式,测试命令就不会跳转。
echo "This, is, a, test, to, remove, commas." | sed -n '{
:start
s/,//1p
t start
}'
5 模式替代。
① &符号,可以用来代表替换命令中的匹配的模式。
echo "The cat sleeps in his hat." | sed 's/.at/"&"/g'
② 替代单独的单词。
#将1234567转换为1,234,567
echo "1234567" | sed '{
:start
s/\(.*[0-9]\)\([0-9]\{3\}\)/\1,\2/
t start
}'
6 创建sed实用工具
sed '$!G' data.txt #加倍行间距
sed '/./,/^$/!d' #删除连续空白行。区间/./到区间/^$/会匹配任何含有至少一个字符的行,到结束空白行,这个区间的行不会删除
sed '/./,$!d' #删除开头的空白行
#删除结尾的空白行。改组命令会匹配只含有一个换行符的行,如果找到了这样的行,而且还是最后一行,删除命令会删掉它;如果不是最后一行,N命令会将下一行附加到它后面。
sed '{
:start
/^\n*$/{$d ; N ; b start}
}' data.txt
sed 's/<[^>]*>//g ; /^$/d' #删除html标签,并删除多余的空白行
第二十二章 Gawk进阶
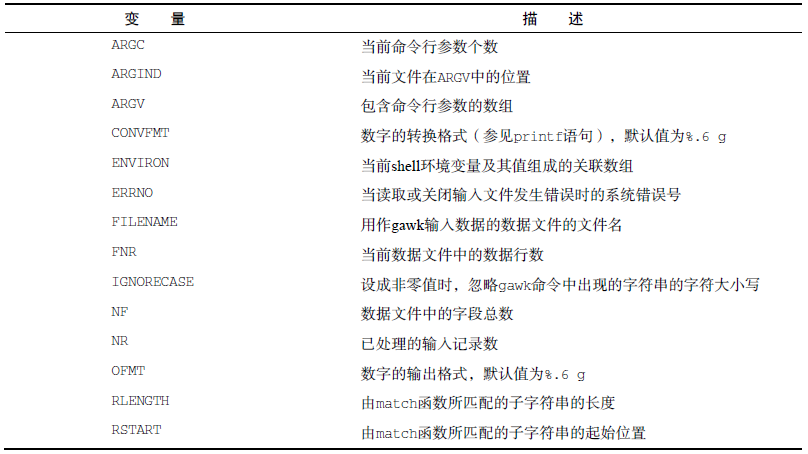
1 使用变量。gawk支持两种不同类型的变量,内建变量和自定义变量。
① 内建变量。分数据字段和记录分割符变量及数据变量。
a 数据字段和记录变量,如下表所示。其中FS和OFS定义了gawk如何处理数据流中的数据字段,默认是一个空格;RS和ORS定义了gawk如何处理数据流中的字段,默认是换行符。默认的RS表明,输入数据流中的每行新文本就是一条新纪录;FIFLDWIDTHS允许你不依靠字符分割符来读取数据,一旦设定了FIFLDWIDTHS变量,gawk就会忽略FS变量。

# data.txt
Riley Mullen
123 Main Street
Chicago, IL
555-1234
Frank Williams
456 Oak Street
Indianapolis In
555-9876
# gawk 'BEGIN{FS="\n";RS=""} {print $1,$4}' data.txt #打印姓名和电话
b 数据变量。除了字段和记录分隔符变量外,gawk还提供了其他一些内建变量来帮助你了解数据发生了什么变化,下表列出了其他内建变量。跟Shell变量不同,在脚本中引用gawk变量时变量名不加美元符号。
② 自定义变量。gawk自定义变量可以时任意数目的字母、数字和下划线,但不能以数字开头。gawk变量区分大小写。
#脚本中给变量赋值
gawk 'BEGIN{X=4; x=x*2+3; print x}'
#命令行上给变量赋值
#script1
BEGIN{FS=","}
{print $1}
gawk -f script1 n=3 data.txt #加入-v选项可以使得命令行参数定义的变量在BEGIN代码之前设定变量 gawk -v n=3 -f script1 data.txt
2 处理数组。gawk语言使用关联数组提供数组功能。
gawk 'BEGIN{
var["a"]=1
var["b"]=2
var["c"]=3
for (test in var)
{
print "Index:",test,"-value:",var[test]
}
delete var["c"]
}'
3 使用模式。
① 正则表达式。使用时,正则表达式必须出现在它要控制的程序脚本的左花括号前。
gawk 'BEGIN{FS=","} /.d/{print $1}' data.txt
gawk 'BEGIN{FS=","} $2 ~ /^data2/{print $0}' data.txt #匹配操作符~允许将正则表达式限定在记录中的特定数据字段。可在~前加上!来排除正则表达式的匹配。
② 数学表达式。
gawk -F: '$4==0{print $1}' /etc/passwd
4 结构化命令。if-else,while,for用法类似C语言。
5 格式化打印。下表时格式化指定符的控制字母表。
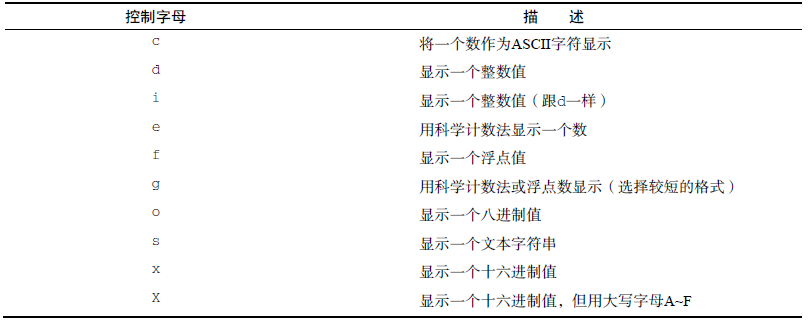
gawk 'BEGIN{FS="\n"; RS=""}{printf "%-16s %s\n", $1, $4}' data.txt #默认为右对齐,加上减号-为左对齐,
6 内建函数。
① gawk支持以下内建数学函数。

除上述标准数学函数,gawk还支持一些按位操作数据的函数:and(v1,v2),or(v1,v2),lshift(val,count),rshift(val,count),xor(v1,v2),compl(val)。
② 字符串函数。gawk支持的字符串函数如下表所示。


③ 时间函数。gawk的时间函数如下表。

7 自定义函数。
gawk '
function myprint()
{
print "%-16s - %s\n", $1, $4
}
BEGIN{FS="\n"; RS=""}
{
myprint()
}' data.txt
gawk -f funclib -f script data.txt #要使用库,只要创建一个含有你gawk程序的文件,然后在命令行上同时指定库文件和程序文件。
第二十三章 使用其他Shell
1 在大多数Linux发行版上,/bin/sh文件链接到shell程序/bin/bash,很遗憾,Ubuntu Linux发行版链接到的时/bin/dash。Dash shell支持的功能没有bash shell多。
2 Zsh shell通常会用在编程环境中,因为它为脚本程序员提供了许多好的功能。
感兴趣可以翻阅原书进行扩展学习。
第四部分 创建实用的脚本
这一部分结合前面学到的Linux命令行和Shell脚本知识,写了一些实用的工具脚本,还涉及到了数据库、Web及电子邮件等内容。需要实践实践再实践!
参考文献
[1] Linux命令行与Shell脚本编程大全. 第三版. Richard Blum, Christine Bresnahan著.



