
写在前面
本篇主要介绍15年ImageNet的冠军ResNet。在不断加神经网络的深度时,会出现一个Degradation的问题,即准确率会先上升然后达到饱和,再持续增加深度则会导致准确率下降。 这并不是过拟合的问题,因为不光在测试集上误差增大,训练集本身误差也会增大。假设有一个比较浅的网络达到了饱和的准确率,那么后面再加上几个的全等映射层,起码误差不会增加,即更深的网络不应该带来训练集上误差上升。而这里提到的使用全等映射直接将前一层输出传到后面的思想,就是ResNet的灵感来源。假定某段神经网络的输入是x,期望输出是H(x),如果我们直接把输入x传到输出作为初始结果,那么此时我们需要学习的目标就是F(x)=H(x)-x。ResNet的结构可以极快地加速超深神经网络的训练,模型的准确率也有非常大的提升。
技术要点
一、网络结构中有很多block组成,每个block的构成如下图所示,加入一个shortcut connections从函数上来看就是加入了全等映射。
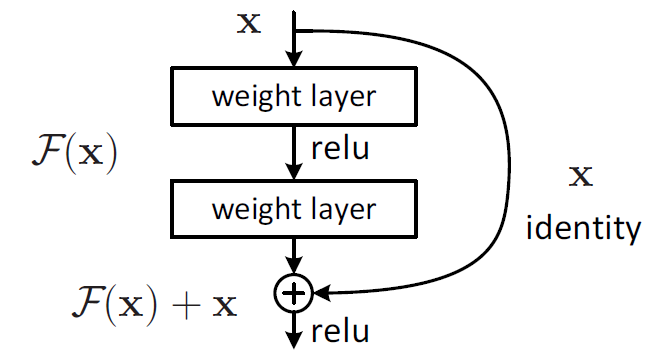
从正向传播来看,引入全等映射可以使网络参数调整最用变大。引用知乎上的一个回答。
F是求和前网络映射,H是从输入到求和后的网络映射。比如把5映射到5.1,那么引入残差前是F'(5)=5.1,引入残差后是H(5)=5.1, H(5)=F(5)+5, F(5)=0.1。这里的F'和F都表示网络参数映射,引入残差后的映射对输出的变化更敏感。比如s输出从5.1变到5.2,映射F'的输出增加了1/51=2%,而对于残差结构输出从5.1到5.2,映射F是从0.1到0.2,增加了100%。明显后者输出变化对权重的调整作用更大,所以效果更好。残差的思想都是去掉相同的主体部分,从而突出微小的变化,看到残差网络我第一反应就是差分放大器。
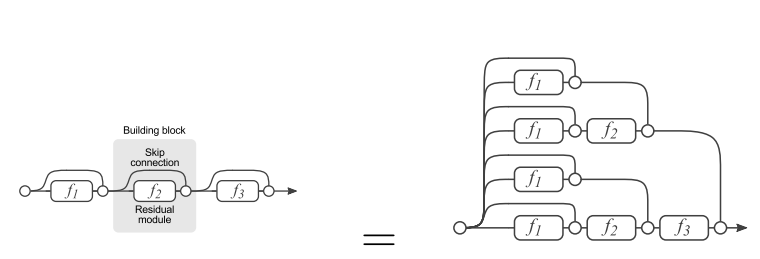
二、残差网络可以从另一个角度理解,如下图所示,残差网络可以看成是由多种路径组合的一个网络,即,残差网络其实是很多并行子网络的组合。
网络结构
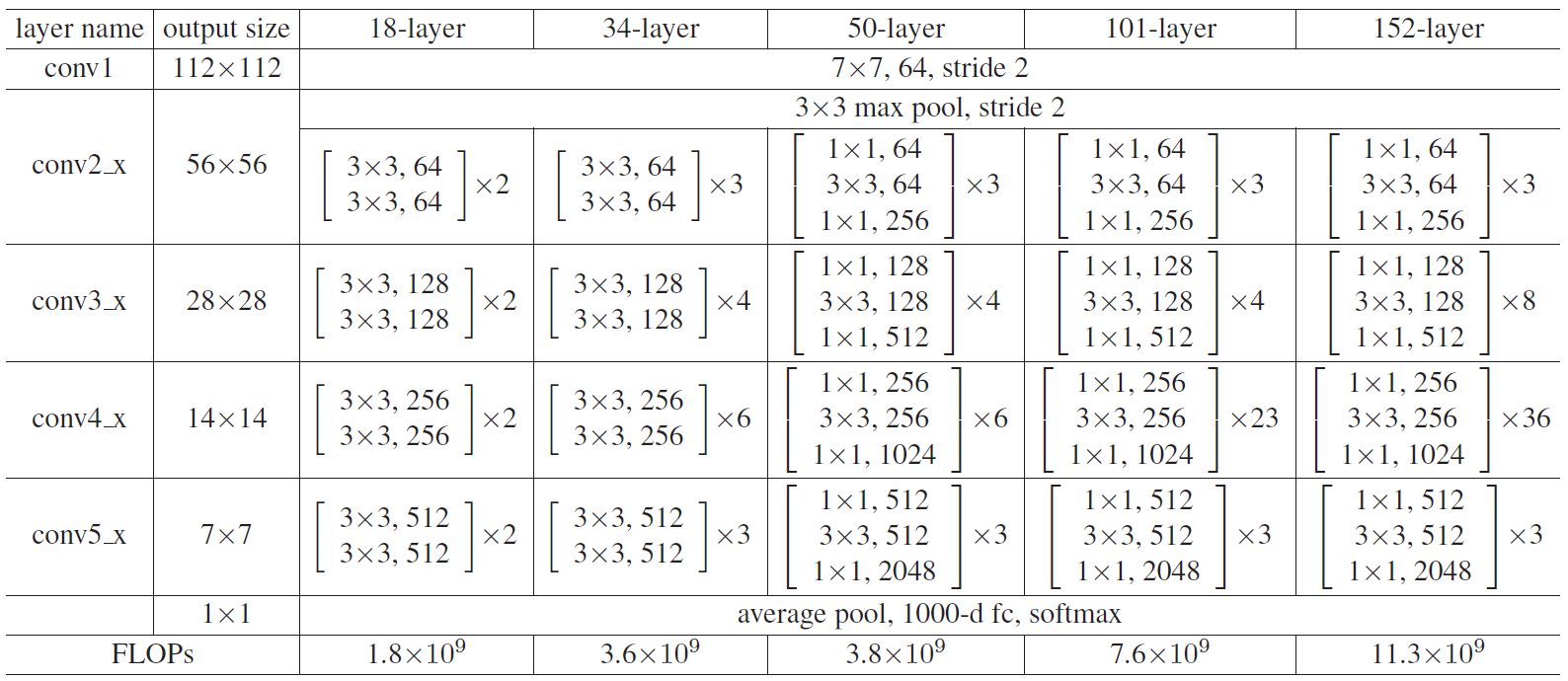
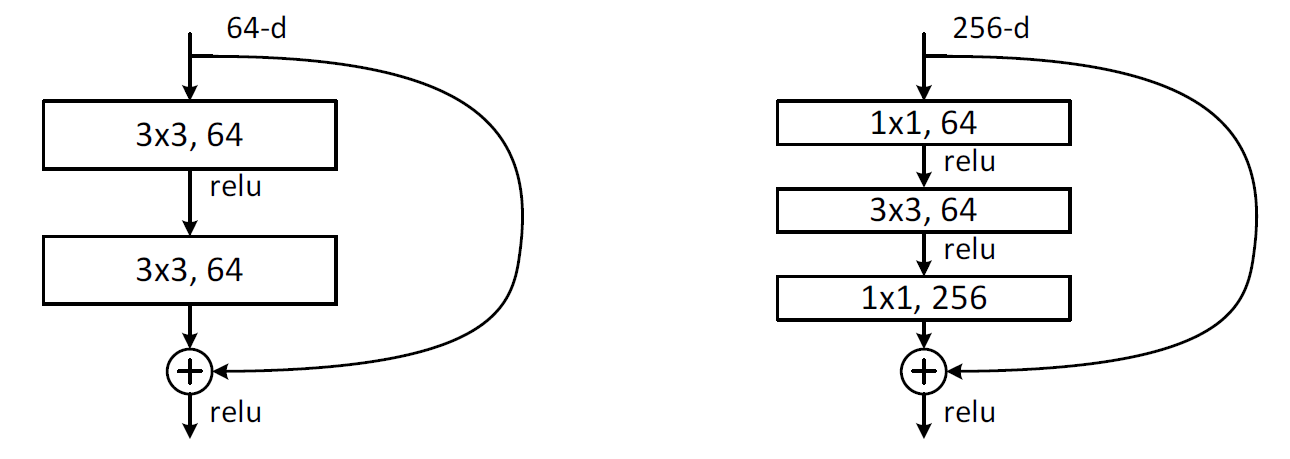
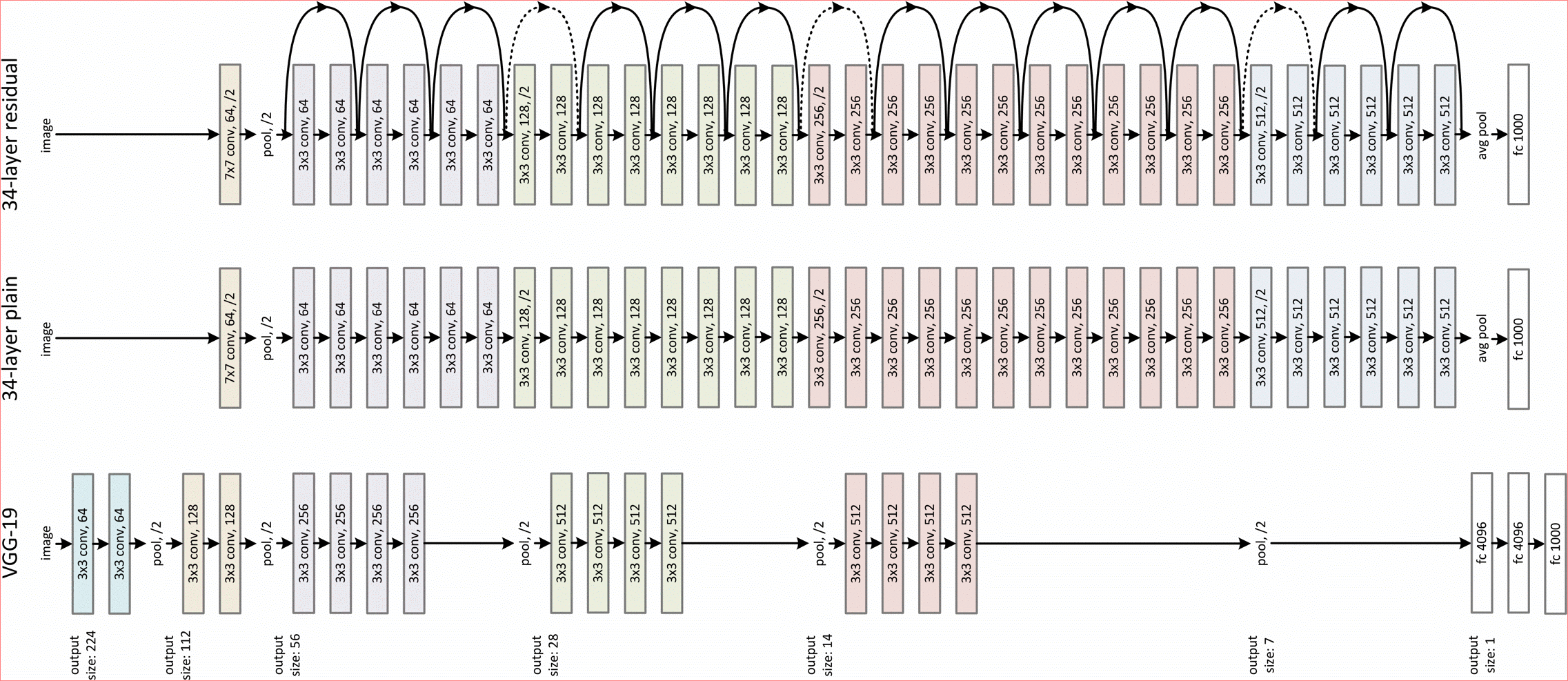
网络整体结构图示如下。其中第二图左图是ResNet-18、ResNet-34的残差模块,右图是ResNet-50,ResNet-101,ResNet-152的残差模块。
代码
#-*- coding: UTF-8 -*-
"""
Environment: Keras2.0.5,Python2.7
Model: ResNet
"""
from __future__ import division
from keras.models import Model
from keras.layers import Conv2D, MaxPooling2D, AveragePooling2D
from keras.layers import Input, Activation, Dense, Flatten
from keras.layers.merge import add
from keras.layers.normalization import BatchNormalization
from keras.regularizers import l2
from keras import backend as K
from keras.utils import plot_model
import six
def _handle_dim_ordering():
global ROW_AXIS
global COL_AXIS
global CHANNEL_AXIS
if K.image_dim_ordering() == 'tf':
ROW_AXIS = 1
COL_AXIS = 2
CHANNEL_AXIS = 3
else:
CHANNEL_AXIS = 1
ROW_AXIS = 2
COL_AXIS = 3
def _get_block(identifier):
if isinstance(identifier, six.string_types):
res = globals().get(identifier)
if not res:
raise ValueError('Invalid {}'.format(identifier))
return res
return identifier
def _bn_relu(input):
"""
Helper to build a BN -> relu block
"""
norm = BatchNormalization(axis=CHANNEL_AXIS)(input)
return Activation("relu")(norm)
def _conv_bn_relu(**conv_params):
"""
Helper to build a conv -> BN -> relu block
"""
filters = conv_params["filters"]
kernel_size = conv_params["kernel_size"]
strides = conv_params.setdefault("strides", (1, 1))
kernel_initializer = conv_params.setdefault("kernel_initializer", "he_normal")
padding = conv_params.setdefault("padding", "same")
kernel_regularizer = conv_params.setdefault("kernel_regularizer", l2(1.e-4))
def f(input):
conv = Conv2D(filters=filters, kernel_size=kernel_size,strides=strides, padding=padding,kernel_initializer=kernel_initializer,kernel_regularizer=kernel_regularizer)(input)
return _bn_relu(conv)
return f
def _bn_relu_conv(**conv_params):
"""
Helper to build a BN -> relu -> conv block.
This is an improved scheme proposed in http://arxiv.org/pdf/1603.05027v2.pdf
"""
filters = conv_params["filters"]
kernel_size = conv_params["kernel_size"]
strides = conv_params.setdefault("strides", (1, 1))
kernel_initializer = conv_params.setdefault("kernel_initializer", "he_normal")
padding = conv_params.setdefault("padding", "same")
kernel_regularizer = conv_params.setdefault("kernel_regularizer", l2(1.e-4))
def f(input):
activation = _bn_relu(input)
return Conv2D(filters=filters, kernel_size=kernel_size,strides=strides, padding=padding, kernel_initializer=kernel_initializer, kernel_regularizer=kernel_regularizer)(activation)
return f
def _shortcut(input, residual):
"""
Adds a shortcut between input and residual block and merges them with "sum"
"""
# Expand channels of shortcut to match residual.
# Stride appropriately to match residual (width, height)
# Should be int if network architecture is correctly configured.
input_shape = K.int_shape(input)
residual_shape = K.int_shape(residual)
stride_width = int(round(input_shape[ROW_AXIS] / residual_shape[ROW_AXIS]))
stride_height = int(round(input_shape[COL_AXIS] / residual_shape[COL_AXIS]))
equal_channels = input_shape[CHANNEL_AXIS] == residual_shape[CHANNEL_AXIS]
shortcut = input
# 1 X 1 conv if shape is different. Else identity.
if stride_width > 1 or stride_height > 1 or not equal_channels:
shortcut = Conv2D(filters=residual_shape[CHANNEL_AXIS], kernel_size=(1, 1), strides=(stride_width, stride_height), padding="valid", kernel_initializer="he_normal",kernel_regularizer=l2(0.0001))(input)
return add([shortcut, residual])
def _residual_block(block_function, filters, repetitions, is_first_layer=False):
"""
Builds a residual block with repeating bottleneck blocks.
"""
def f(input):
for i in range(repetitions):
init_strides = (1, 1)
if i == 0 and not is_first_layer:
init_strides = (2, 2)
input = block_function(filters=filters, init_strides=init_strides, is_first_block_of_first_layer=(is_first_layer and i == 0))(input)
return input
return f
def basic_block(filters, init_strides=(1, 1), is_first_block_of_first_layer=False):
"""
Basic 3 X 3 convolution blocks for use on resnets with layers <= 34.
Follows improved proposed scheme in http://arxiv.org/pdf/1603.05027v2.pdf
"""
def f(input):
if is_first_block_of_first_layer:
# don't repeat bn->relu since we just did bn->relu->maxpool
conv1 = Conv2D(filters=filters, kernel_size=(3, 3),strides=init_strides, padding="same", kernel_initializer="he_normal", kernel_regularizer=l2(1e-4))(input)
else:
conv1 = _bn_relu_conv(filters=filters, kernel_size=(3, 3), strides=init_strides)(input)
residual = _bn_relu_conv(filters=filters, kernel_size=(3, 3))(conv1)
return _shortcut(input, residual)
return f
def bottleneck(filters, init_strides=(1, 1), is_first_block_of_first_layer=False):
"""
Bottleneck architecture for > 34 layer resnet.
Follows improved proposed scheme in http://arxiv.org/pdf/1603.05027v2.pdf
Returns:
A final conv layer of filters * 4
"""
def f(input):
if is_first_block_of_first_layer:
# don't repeat bn->relu since we just did bn->relu->maxpool
conv_1_1 = Conv2D(filters=filters, kernel_size=(1, 1), strides=init_strides, padding="same", kernel_initializer="he_normal", kernel_regularizer=l2(1e-4))(input)
else:
conv_1_1 = _bn_relu_conv(filters=filters, kernel_size=(1, 1), strides=init_strides)(input)
conv_3_3 = _bn_relu_conv(filters=filters, kernel_size=(3, 3))(conv_1_1)
residual = _bn_relu_conv(filters=filters * 4, kernel_size=(1, 1))(conv_3_3)
return _shortcut(input, residual)
return f
class ResnetBuilder(object):
@staticmethod
def build(input_shape, num_outputs, block_fn, repetitions):
"""
Builds a custom ResNet like architecture.
Args:
input_shape: The input shape in the form (nb_channels, nb_rows, nb_cols)
num_outputs: The number of outputs at final softmax layer
block_fn: The block function to use. This is either `basic_block` or `bottleneck`.The original paper used basic_block for layers < 50
repetitions: Number of repetitions of various block units.At each block unit, the number of filters are doubled and the input size is halved
Returns:
The keras `Model`.
"""
_handle_dim_ordering()
if len(input_shape) != 3:
raise Exception("Input shape should be a tuple (nb_channels, nb_rows, nb_cols)")
# Permute dimension order if necessary
if K.image_dim_ordering() == 'tf':
input_shape = (input_shape[1], input_shape[2], input_shape[0])
# Load function from str if needed.
block_fn = _get_block(block_fn)
input = Input(shape=input_shape)
conv1 = _conv_bn_relu(filters=64, kernel_size=(7, 7), strides=(2, 2))(input)
pool1 = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), padding="same")(conv1)
block = pool1
filters = 64
for i, r in enumerate(repetitions):
block = _residual_block(block_fn, filters=filters, repetitions=r, is_first_layer=(i == 0))(block)
filters *= 2
# Last activation
block = _bn_relu(block)
# Classifier block
block_shape = K.int_shape(block)
pool2 = AveragePooling2D(pool_size=(block_shape[ROW_AXIS], block_shape[COL_AXIS]), strides=(1, 1))(block)
flatten1 = Flatten()(pool2)
dense = Dense(units=num_outputs, kernel_initializer="he_normal", activation="softmax")(flatten1)
model = Model(inputs=input, outputs=dense)
return model
@staticmethod
def build_resnet_18(input_shape, num_outputs):
return ResnetBuilder.build(input_shape, num_outputs, basic_block, [2, 2, 2, 2])
@staticmethod
def build_resnet_34(input_shape, num_outputs):
return ResnetBuilder.build(input_shape, num_outputs, basic_block, [3, 4, 6, 3])
@staticmethod
def build_resnet_50(input_shape, num_outputs):
return ResnetBuilder.build(input_shape, num_outputs, bottleneck, [3, 4, 6, 3])
@staticmethod
def build_resnet_101(input_shape, num_outputs):
return ResnetBuilder.build(input_shape, num_outputs, bottleneck, [3, 4, 23, 3])
@staticmethod
def build_resnet_152(input_shape, num_outputs):
return ResnetBuilder.build(input_shape, num_outputs, bottleneck, [3, 8, 36, 3])
def check_print():
# Create a Keras Model
model=ResnetBuilder.build_resnet_34((3, 224, 224), 100)
model.summary()
# Save a PNG of the Model Build
plot_model(model,to_file='ResNet.png')
model.compile(optimizer='sgd',loss='categorical_crossentropy')
print 'Model Compiled'
if __name__=='__main__':
check_print()
参考文献
[1] ResNet, Deep Residual Learning for Image Recognition.
[2] 关于残差网络Resnet的理解.
[3] 对ResNet的理解.
[4] keras-resnet.



